在编程中如果能够熟悉shell高阶语法,将对我们进阶为高级程序员有很大的帮助,本文将从Shell重定向 管道命令 awk编程 sed等方面展开介绍。
作者:有勇气的牛排
Table of Contents
1 shell重定向
通常情况下,多数unix系统命令从终端接受输入并将产生的结果输出发送回终端。
一个命令通常从一个标准输入的地方读取,这里恰好终端。同样,一个命令通常将其输出写入到标准输出,治理默认也是终端。
重定向命令列表
| 命令 |
描述 |
| command > file |
将输出重定向到file |
| conmand < file |
将输入重定向到file |
| n > file |
将文件描述符为n的文件重定向到file |
| n >> file |
将文件描述符为n的文件,以追加的方式重定向到file |
| n >& m |
将输出文件 m 和 n 合并 |
| n <& m |
将输入文件 m 和 n 合并 |
| << tag |
将开始标记tag和结束标记tag之间的内容作为输入 |
1.1 输出重定向
>:覆盖到文件
>>:追加到文件末尾
实例:使用who命令,将结果保存在who.txt中
who > who.txt
1.2 /dev/null
这条命令可以让执行的命令,不在屏幕上显示结果(类似于禁止输出),其本质为写一个特殊的文件,但是写的文件都会被抛弃。
who /dev/null
2 linux管道命令
- 符号:
|
- 管道命令能且仅能处理经由前一个命令传来的正确信息。(不处理错误输出)
- 在每个管道符号后面接的第一个参数一定是命令,并且该命令必须能够接收标准输入
哈喽,大家好,我是[有勇气的牛排](全网同名)🐮🐮🐮
有问题的小伙伴欢迎在文末[评论,点赞、收藏]是对我最大的支持!!!。
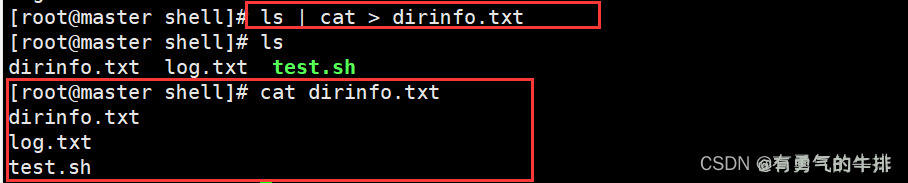
实例1:将ls的标准输出,利用cat命令写到文件中
ls | cat > dirinfo.txt
实例2:查询指定字符
人生得意须尽欢,莫使金樽空对月。
天生我材必有用,千金散尽还复来。
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,君莫停。
与君歌一曲,请君为我侧耳听。
钟鼓馔玉不足贵,但愿长醉不愿醒。
古来圣贤皆寂寞,惟有饮者留其名。
陈王昔时宴平乐,斗酒十千恣欢谑。
主人何为言少钱,径须沽取对君酌。
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。
cat gushi.txt | grep "请君为我侧耳听"

实例3:生成一个8位随机密码
tr -dc A-Za-z0-9_ </dev/urandom | head -c 8 | xargs
3 grep 搜索命令
grep(global search regular expression(RE) and print out the line)
语法: grep [选项] "搜索内容" 文件名
-a 不要忽略二进制数据。
-A 数字: 列出符合条件的行,并列出后续的n行
-B 数字: 列出符合条件的行,并列出前面的n行
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c: 统计找到的符合条件的字符串的次数
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 输出行号
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反向查找
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分
--color=auto 搜索出的关键字用颜色显示
test.txt
人生得意须尽欢,莫使金樽空对月。666
天生我材必有用,千金散尽还复来。666777
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,君莫停。
与君歌一曲,请君为我侧耳听。666
实例:查询包含666,不包括777的句子
grep "666" test.txt | grep -v "777"
实例:查出/usr/local/nginx/logs目录中的所有log文件,并且过滤出包含couragesteak的行。
find /usr/local/nginx/logs -type f -name "*.log" | xargs grep "couragesteak"
4 cut 列提取命令
语法:cut [选项] 文件名
-f:列号:提取第几列
-d:分割符:按照指定分隔符分割列,默认为 “tab” 制表符
-n:取消分割多字节字符
-c:字符范围:不依赖分隔符来区分,而是通过字符范围(行首为0)来进行字段提取。“n-”表示从第n个字符到行尾;“n-m”从第n个字符到第m个字符;“一m”表示从第1个字符到第m个字符。
--complemment:补足被选择的字节、字符或字段
--out-delimiter:指定输出内容是的字段分割符
students.txt
id name score
1 Charles 100
2 Tom 99
3 Lisa 99
实例:提取第2、3列内容
cut -f 2,3 student.txt

实例:提取每行前2个字符
cut -c -2 student.txt
实例:提取第2到最后一个字符
cut -c 2- student.txt
cat student.txt | cut -d " " -f 1,2
5 awk命令
AWK是处理文本文件的语言,是一个强大的文本分析工具。
- 多个条件使用{ }进行分割,也可以使用回车符进行分割
- 如需执行多个命令,可使用回车或
; 进行分割
- 在awk中,变量的赋值与调用都不需要加入
$ 符
5.1 awk 条件
| 条件 |
条件类型 |
描述 |
| BEGIN |
awk保留字 |
BEGIN作为awk的保留字,其在awk读取数据之前执行,且执行一次。 |
| END |
awk保留字 |
END作为awk的保留字,与BEGIN的作用相反,其在程序执行结束后,执行的一次动作。 |
| > |
关系运算符 |
大于 |
| < |
关系运算符 |
小于 |
| >= |
关系运算符 |
大于等于 |
| <= |
关系运算符 |
小于等于 |
| == |
关系运算符 |
判断是否相等 |
| != |
关系运算符 |
不等于 |
| A=B |
关系运算符 |
判断字符串中是否包含B表达式的字串 |
| A!=B |
关系运算符 |
判断字符串中是否不包含B表达式的字串 |
| /正则/ |
正则表达式 |
正则 |
5.1.1 BEGIN
BEGIN作为awk的保留字,其在awk读取数据之前执行,且执行一次。
实例:
awk 'BEGIN{printf "先执行我这哦\n"} {printf $2"\n"}' student.txt

5.1.2 END
END作为awk的保留字,与BEGIN的作用相反,其在程序执行结束后,执行的一次动作。
实例:
awk 'END{printf "程序执行完毕,执行这里哈\n"} {printf $2 "\t" $3 "\n"}' student.txt

5.1.3 关系运算符
实例
cat student.txt | grep -v score | awk '$3 > 99 {printf $2 "\t" $3 "\n"}'
5.1.4 正则
实例:打印Chrles的信息
awk '/Charles/ {print}' student.txt
5.2 awk 内置变量
| 内置变量 |
描述 |
| $0 |
打印所有数据 |
| $n |
当前记录的第n列字段 |
| NF |
当前所在行总字段数 |
| NR |
当前所在行的行号 |
| … |
… |
awk '{print $0}' student.txt
awk '{print $n}' student.txt
awk '{print NF}' student.txt
awk '{print NR}' student.txt
awk 'END{print NR}' student.txt
awk 'NR==1{print}' student.txt
sed -n "2, 1p" student.txt | awk '{print $1}'
ps -aux | grep watchdog
ps -aux | grep watchdog | awk '{print $1"\t"$2"\t"$3}'
ps -aux | grep watchdog | awk 'NR==1{print $1"\t"$2"\t"$3}'
df -h | awk 'END{print NR}'
ps -aux | grep watchdog | awk 'END{print NF}'
ps -aux | grep watchdog | awk 'END{print $NF}'
5.3 awk 脚本
对于简单的命令可以在命令行中解决,但是面对大量从操作时,写成脚本就非常中重要了。
使用 -f 进行调用
print.awk
{print $1"\t"$2"\t"$3}
ps -aux | grep watchdog | awk -f print.awk
6 sed
sed命令是利用脚本来处理文本文件,并且可以按照执行编辑文本文件。
参数说明:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或--help 显示帮助。
-n或--quiet或--silent 仅显示script处理后的结果。
-V或--version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 1,20s/old/new/g 就是啦!
6.1 查、删除、替换、增加、批量操作
注:这里nl与cat效果相同
6.1.1 查
实例:查询第2行记录
sed -n '2p' student.txt

实例:查询2~4行
sed -n '2,4p' student.txt

6.1.2 增加
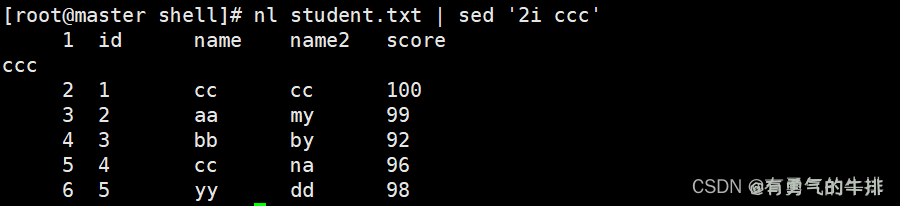
实例:在第二行前 插入 ccc,并标准输出
nl student.txt | sed '2i ccc'
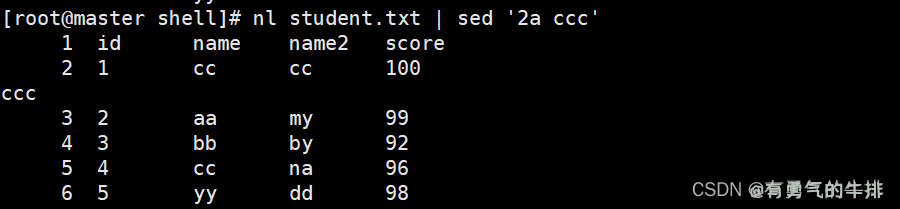
实例:在第二行后 插入 ccc,并标准输出
nl student.txt | sed '2a ccc'
6.1.3 删除
实例:删除3~4行,并标准输出
nl student.txt | sed '3,4d'

实例:删除第3~最后一行,并标准输出
cat student.txt | sed '3,$d'

6.1.4 替换
6.1.4.1 -e 不修改源文件
id name name2 score
1 cc cc 100
2 aa my 99
3 bb by 92
4 cc na 96
5 yy dd 98
语法:sed s/被替换的字符串/新字符串/g
实例1:将每行第一次出现的 cc 替换为导演,并标准输出
sed -e 's/cc/导演/' student.txt

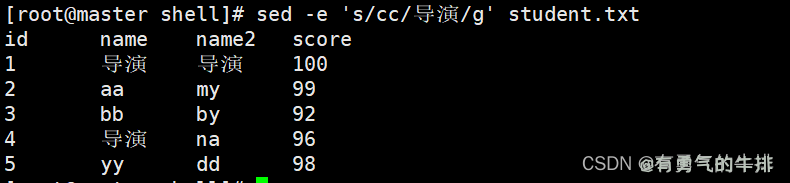
实例2:基于实例1,替换所有符合条件的
sed -e 's/cc/导演/g' student.txt
6.1.4.2 -i 修改源文件
用法同-e,区别在于是否修改源文件。
sed -e 's/cc/导演/' student.txt
sed -e 's/cc/导演/g' student.txt
6.1.4.3 范围替换
实例:将 2~5行替换为空
nl student.txt | sed '2,5c 空空空'

6.1.4.4 批量操作
将当前目录所有stu开头的文件进行操作
sed -i 's/导演/cc/g' stu*
6.2 搜索
id name score
1 Charles 100
1 Charles_a 99
3 Lisa 92
2 Tom 99
3 Lisa_b 95
6.2.1 仅搜索
实例:搜索包含 cc的记录,并标准输出。
cat student.txt | sed -n '/cc/p'
6.2.2 搜索并执行指令
实例:搜索第一个匹配到的cc记录,并且将第一个cc替换为`导演,最后标准输出。
cat student.txt | sed -n '/cc/{s/cc/导演/;p;q}'

实例:搜索所有含有cc的记录,将第一个出现的cc替换为导演,并标准输出。
cat student.txt | sed -n '/cc/{s/cc/导演/;p}'

7 字符处理命令
7.1 sort 排序
语法:sort [选项] 文件名
-b: 忽略每行前面的空格字符
-c: 检查文件是否已经按照顺序排序
-d: 处理英文字母、数字及空格字符外,忽略其他的字符
-f: 忽略大小写
-i: 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-n: 以数值型进行排序,默认使用字符串型排序
-r: 反向排序
-u: 删除重复行。就是uniq命令
-t: 指定分隔符,默认是分隔符是制表符
-k n[,m]: ―按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
7.2 uniq 取消重复行
语法:uniq [选项] 文件名
-i:忽略大小写
实例
sort -n student.txt | uniq
7.3 wc 统计命令
语法:wc [选项] 文件名
选项:
-l:只统计行数
-w:只统计单词数
-m:只统计字符数
统计:student.txt
[root@master shell]
6 24 76 student.txt
行数为6、单词数24、字节数76
<blockquote>
<p>在编程中如果能够熟悉shell高阶语法,将对我们进阶为高级程序员有很大的帮助,本文将从Shell重定向 管道命令 awk编程 sed等方面展开介绍。<br />
作者:有勇气的牛排</p>
</blockquote>
<p><h3>Table of Contents</h3><ul><ul><li><a href="#1_shell_4">1 shell重定向</a></li><ul><li><a href="#11__21">1.1 输出重定向</a></li><li><a href="#12_devnull_31">1.2 /dev/null</a></li></ul><li><a href="#2_linux_38">2 linux管道命令</a></li><li><a href="#3_grep__82">3 grep 搜索命令</a></li><li><a href="#4_cut__138">4 cut 列提取命令</a></li><li><a href="#5_awk_176">5 awk命令</a></li><ul><li><a href="#51_awk__183">5.1 awk 条件</a></li><ul><li><a href="#511_BEGIN_200">5.1.1 BEGIN</a></li><li><a href="#512_END_209">5.1.2 END</a></li><li><a href="#513__219">5.1.3 关系运算符</a></li><li><a href="#514__225">5.1.4 正则</a></li></ul><li><a href="#52_awk__230">5.2 awk 内置变量</a></li><li><a href="#53_awk__273">5.3 awk 脚本</a></li></ul><li><a href="#6_sed_285">6 sed</a></li><ul><li><a href="#61__304">6.1 查、删除、替换、增加、批量操作</a></li><ul><li><a href="#611__308">6.1.1 查</a></li><li><a href="#612__325">6.1.2 增加</a></li><li><a href="#613__342">6.1.3 删除</a></li><li><a href="#614__359">6.1.4 替换</a></li><ul><li><a href="#6141_e__360">6.1.4.1 -e 不修改源文件</a></li><li><a href="#6142_i__388">6.1.4.2 -i 修改源文件</a></li><li><a href="#6143__398">6.1.4.3 范围替换</a></li><li><a href="#6144__407">6.1.4.4 批量操作</a></li></ul></ul><li><a href="#62__413">6.2 搜索</a></li><ul><li><a href="#621__422">6.2.1 仅搜索</a></li><li><a href="#622__427">6.2.2 搜索并执行指令</a></li></ul></ul><li><a href="#7__444">7 字符处理命令</a></li><ul><li><a href="#71_sort__445">7.1 sort 排序</a></li><li><a href="#72_uniq__462">7.2 uniq 取消重复行</a></li><li><a href="#73_wc__472">7.3 wc 统计命令</a></li></ul></ul></ul></p>
<h2><a id="1_shell_4"></a>1 shell重定向</h2>
<p>通常情况下,多数unix系统命令从终端接受输入并将产生的结果输出发送回终端。</p>
<p>一个命令通常从一个标准输入的地方读取,这里恰好终端。同样,一个命令通常将其输出写入到标准输出,治理默认也是终端。</p>
<p>重定向命令列表</p>
<table>
<thead>
<tr>
<th>命令</th>
<th>描述</th>
</tr>
</thead>
<tbody>
<tr>
<td>command > file</td>
<td>将输出重定向到file</td>
</tr>
<tr>
<td>conmand < file</td>
<td>将输入重定向到file</td>
</tr>
<tr>
<td>n > file</td>
<td>将文件描述符为n的文件重定向到file</td>
</tr>
<tr>
<td>n >> file</td>
<td>将文件描述符为n的文件,以追加的方式重定向到file</td>
</tr>
<tr>
<td>n >& m</td>
<td>将输出文件 m 和 n 合并</td>
</tr>
<tr>
<td>n <& m</td>
<td>将输入文件 m 和 n 合并</td>
</tr>
<tr>
<td><< tag</td>
<td>将开始标记tag和结束标记tag之间的内容作为输入</td>
</tr>
</tbody>
</table>
<h3><a id="11__21"></a>1.1 输出重定向</h3>
<p><code>></code>:覆盖到文件<br />
<code>>></code>:追加到文件末尾</p>
<p>实例:使用who命令,将结果保存在who.txt中</p>
<pre><div class="hljs"><code class="lang-powershell">who > who.txt
</code></div></pre>
<h3><a id="12_devnull_31"></a>1.2 /dev/null</h3>
<p>这条命令可以让执行的命令,不在屏幕上显示结果(类似于禁止输出),其本质为写一个特殊的文件,但是写的文件都会被抛弃。</p>
<pre><div class="hljs"><code class="lang-powershell">who /dev/null
</code></div></pre>
<h2><a id="2_linux_38"></a>2 linux管道命令</h2>
<ul>
<li>符号:<code>|</code></li>
<li>管道命令能且仅能处理经由前一个命令传来的正确信息。(不处理错误输出)</li>
<li>在每个管道符号后面接的第一个参数一定是命令,并且该命令必须能够接收标准输入</li>
</ul>
<p><font face="楷体,华文行楷,隶书,黑体" color="red" size="4"><strong>哈喽,大家好,我是[有勇气的牛排](全网同名)🐮🐮🐮</strong></font></p>
<p><font face="楷体,华文行楷,隶书,黑体" color="blue" size="4"><strong>有问题的小伙伴欢迎在文末[评论,点赞、收藏]是对我最大的支持!!!。</strong></font></p>
<p>实例1:将ls的标准输出,利用cat命令写到文件中</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">ls</span> | <span class="hljs-built_in">cat</span> > dirinfo.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/fe75f529f83a6dcb994cd99b8f8d4eb9.png" alt="image.png" /></p>
<p>实例2:查询指定字符</p>
<pre><div class="hljs"><code class="lang-powershell">人生得意须尽欢,莫使金樽空对月。
天生我材必有用,千金散尽还复来。
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,君莫停。
与君歌一曲,请君为我侧耳听。
钟鼓馔玉不足贵,但愿长醉不愿醒。
古来圣贤皆寂寞,惟有饮者留其名。
陈王昔时宴平乐,斗酒十千恣欢谑。
主人何为言少钱,径须沽取对君酌。
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。
</code></div></pre>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> gushi.txt | grep <span class="hljs-string">"请君为我侧耳听"</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/72b76688629ce53e6e0beb01f4dbd07e.png" alt="image.png" /></p>
<p>实例3:生成一个8位随机密码</p>
<pre><div class="hljs"><code class="lang-powershell">tr <span class="hljs-literal">-dc</span> A<span class="hljs-literal">-Za-z0-9_</span> </dev/urandom | head <span class="hljs-literal">-c</span> <span class="hljs-number">8</span> | xargs
</code></div></pre>
<h2><a id="3_grep__82"></a>3 grep 搜索命令</h2>
<p>grep(global search regular expression(RE) and print out the line)</p>
<p>语法: <code>grep [选项] "搜索内容" 文件名</code></p>
<pre><div class="hljs"><code class="lang-shell">-a 不要忽略二进制数据。
-A 数字: 列出符合条件的行,并列出后续的n行
-B 数字: 列出符合条件的行,并列出前面的n行
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c: 统计找到的符合条件的字符串的次数
-C<显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 输出行号
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反向查找
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分
--color=auto 搜索出的关键字用颜色显示
</code></div></pre>
<p>test.txt</p>
<pre><div class="hljs"><code class="lang-javascript">人生得意须尽欢,莫使金樽空对月。<span class="hljs-number">666</span>
天生我材必有用,千金散尽还复来。<span class="hljs-number">666777</span>
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,君莫停。
与君歌一曲,请君为我侧耳听。<span class="hljs-number">666</span>
</code></div></pre>
<p>实例:查询<code>包含666</code>,<code>不包括777</code>的句子</p>
<pre><div class="hljs"><code class="lang-powershell">grep <span class="hljs-string">"666"</span> test.txt | grep <span class="hljs-literal">-v</span> <span class="hljs-string">"777"</span>
</code></div></pre>
<p>实例:查出<code>/usr/local/nginx/logs</code>目录中的所有log文件,并且过滤出包含<code>couragesteak</code>的行。</p>
<pre><div class="hljs"><code class="lang-powershell">find /usr/local/nginx/logs <span class="hljs-literal">-type</span> f <span class="hljs-literal">-name</span> <span class="hljs-string">"*.log"</span> | xargs grep <span class="hljs-string">"couragesteak"</span>
</code></div></pre>
<h2><a id="4_cut__138"></a>4 cut 列提取命令</h2>
<p><strong>语法:<code>cut [选项] 文件名</code></strong><br />
<code>-f</code>:列号:提取第几列<br />
<code>-d</code>:分割符:按照指定分隔符分割列,默认为 “tab” 制表符<br />
<code>-n</code>:取消分割多字节字符<br />
<code>-c</code>:字符范围:不依赖分隔符来区分,而是通过字符范围(行首为0)来进行字段提取。“n-”表示从第n个字符到行尾;“n-m”从第n个字符到第m个字符;“一m”表示从第1个字符到第m个字符。<br />
<code>--complemment</code>:补足被选择的字节、字符或字段<br />
<code>--out-delimiter</code>:指定输出内容是的字段分割符</p>
<p>students.txt</p>
<pre><div class="hljs"><code class="lang-powershell">id name score
<span class="hljs-number">1</span> Charles <span class="hljs-number">100</span>
<span class="hljs-number">2</span> Tom <span class="hljs-number">99</span>
<span class="hljs-number">3</span> Lisa <span class="hljs-number">99</span>
</code></div></pre>
<p>实例:提取第2、3列内容</p>
<pre><div class="hljs"><code class="lang-powershell">cut <span class="hljs-operator">-f</span> <span class="hljs-number">2</span>,<span class="hljs-number">3</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e351e93fb64f9fbc4333fa83571ff52b.png" alt="image.png" /></p>
<p>实例:提取每行前2个字符</p>
<pre><div class="hljs"><code class="lang-powershell">cut <span class="hljs-literal">-c</span> <span class="hljs-literal">-2</span> student.txt
</code></div></pre>
<p>实例:提取第2到最后一个字符</p>
<pre><div class="hljs"><code class="lang-powershell">cut <span class="hljs-literal">-c</span> <span class="hljs-number">2</span>- student.txt
</code></div></pre>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | cut <span class="hljs-literal">-d</span> <span class="hljs-string">" "</span> <span class="hljs-operator">-f</span> <span class="hljs-number">1</span>,<span class="hljs-number">2</span>
</code></div></pre>
<h2><a id="5_awk_176"></a>5 awk命令</h2>
<p>AWK是处理文本文件的语言,是一个强大的文本分析工具。</p>
<ul>
<li>多个条件使用{ }进行分割,也可以使用回车符进行分割</li>
<li>如需执行多个命令,可使用回车或<code>;</code> 进行分割</li>
<li>在awk中,变量的赋值与调用都不需要加入 <code>$</code> 符</li>
</ul>
<h3><a id="51_awk__183"></a>5.1 awk 条件</h3>
<table>
<thead>
<tr>
<th>条件</th>
<th>条件类型</th>
<th>描述</th>
</tr>
</thead>
<tbody>
<tr>
<td>BEGIN</td>
<td>awk保留字</td>
<td>BEGIN作为awk的保留字,其在awk读取数据之前执行,且执行一次。</td>
</tr>
<tr>
<td>END</td>
<td>awk保留字</td>
<td>END作为awk的保留字,与BEGIN的作用相反,其在程序执行结束后,执行的一次动作。</td>
</tr>
<tr>
<td>></td>
<td>关系运算符</td>
<td>大于</td>
</tr>
<tr>
<td><</td>
<td>关系运算符</td>
<td>小于</td>
</tr>
<tr>
<td>>=</td>
<td>关系运算符</td>
<td>大于等于</td>
</tr>
<tr>
<td><=</td>
<td>关系运算符</td>
<td>小于等于</td>
</tr>
<tr>
<td>==</td>
<td>关系运算符</td>
<td>判断是否相等</td>
</tr>
<tr>
<td>!=</td>
<td>关系运算符</td>
<td>不等于</td>
</tr>
<tr>
<td>A=B</td>
<td>关系运算符</td>
<td>判断字符串中是否包含B表达式的字串</td>
</tr>
<tr>
<td>A!=B</td>
<td>关系运算符</td>
<td>判断字符串中是否不包含B表达式的字串</td>
</tr>
<tr>
<td>/正则/</td>
<td>正则表达式</td>
<td>正则</td>
</tr>
</tbody>
</table>
<h4><a id="511_BEGIN_200"></a>5.1.1 BEGIN</h4>
<p>BEGIN作为awk的保留字,其在awk读取数据之前执行,且执行一次。</p>
<p>实例:</p>
<pre><div class="hljs"><code class="lang-powershell">awk <span class="hljs-string">'BEGIN{printf "先执行我这哦\n"} {printf $2"\n"}'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/74036bc2402d1276feba2c32d527423c.png" alt="image.png" /></p>
<h4><a id="512_END_209"></a>5.1.2 END</h4>
<p>END作为awk的保留字,与BEGIN的作用相反,其在程序执行结束后,执行的一次动作。</p>
<p>实例:</p>
<pre><div class="hljs"><code class="lang-powershell">awk <span class="hljs-string">'END{printf "程序执行完毕,执行这里哈\n"} {printf $2 "\t" $3 "\n"}'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/17a48e540ffb0fd0bcd8ead035f56e42.png" alt="image.png" /></p>
<h4><a id="513__219"></a>5.1.3 关系运算符</h4>
<p>实例</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | grep <span class="hljs-literal">-v</span> score | awk <span class="hljs-string">'$3 > 99 {printf $2 "\t" $3 "\n"}'</span>
</code></div></pre>
<h4><a id="514__225"></a>5.1.4 正则</h4>
<p>实例:打印Chrles的信息</p>
<pre><div class="hljs"><code class="lang-powershell">awk <span class="hljs-string">'/Charles/ {print}'</span> student.txt
</code></div></pre>
<h3><a id="52_awk__230"></a>5.2 awk 内置变量</h3>
<table>
<thead>
<tr>
<th>内置变量</th>
<th>描述</th>
</tr>
</thead>
<tbody>
<tr>
<td>$0</td>
<td>打印所有数据</td>
</tr>
<tr>
<td>$n</td>
<td>当前记录的第n列字段</td>
</tr>
<tr>
<td>NF</td>
<td>当前所在行总字段数</td>
</tr>
<tr>
<td>NR</td>
<td>当前所在行的行号</td>
</tr>
<tr>
<td>…</td>
<td>…</td>
</tr>
</tbody>
</table>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-comment"># 打印所有数据</span>
awk <span class="hljs-string">'{print $0}'</span> student.txt
<span class="hljs-comment"># 当前记录的第n列字段</span>
awk <span class="hljs-string">'{print $n}'</span> student.txt
<span class="hljs-comment"># 当前所在行总字段数</span>
awk <span class="hljs-string">'{print NF}'</span> student.txt
<span class="hljs-comment"># 当前所在行的行号</span>
awk <span class="hljs-string">'{print NR}'</span> student.txt
<span class="hljs-comment"># 打印文本文件的总行数 </span>
awk <span class="hljs-string">'END{print NR}'</span> student.txt
<span class="hljs-comment"># 打印文本第一行</span>
awk <span class="hljs-string">'NR==1{print}'</span> student.txt
<span class="hljs-comment"># 打印文本第二行第一列</span>
sed <span class="hljs-literal">-n</span> <span class="hljs-string">"2, 1p"</span> student.txt | awk <span class="hljs-string">'{print $1}'</span>
<span class="hljs-comment"># 进程查看</span>
<span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog
<span class="hljs-comment"># 进程查看 获取第1、2、3列</span>
<span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog | awk <span class="hljs-string">'{print $1"\t"$2"\t"$3}'</span>
<span class="hljs-comment"># 进程查看 第一行 获取第1、2、3列</span>
<span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog | awk <span class="hljs-string">'NR==1{print $1"\t"$2"\t"$3}'</span>
<span class="hljs-comment"># 获取行数</span>
df <span class="hljs-literal">-h</span> | awk <span class="hljs-string">'END{print NR}'</span>
<span class="hljs-comment"># 获取最后一行的列数</span>
<span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog | awk <span class="hljs-string">'END{print NF}'</span>
<span class="hljs-comment"># 获取最后一列</span>
<span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog | awk <span class="hljs-string">'END{print $NF}'</span>
</code></div></pre>
<h3><a id="53_awk__273"></a>5.3 awk 脚本</h3>
<p>对于简单的命令可以在命令行中解决,但是面对大量从操作时,写成脚本就非常中重要了。</p>
<p>使用 <code>-f</code> 进行调用</p>
<p>print.awk</p>
<pre><div class="hljs"><code class="lang-powershell">{print <span class="hljs-variable">$1</span><span class="hljs-string">"\t"</span><span class="hljs-variable">$2</span><span class="hljs-string">"\t"</span><span class="hljs-variable">$3</span>}
</code></div></pre>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">ps</span> <span class="hljs-literal">-aux</span> | grep watchdog | awk <span class="hljs-operator">-f</span> print.awk
</code></div></pre>
<h2><a id="6_sed_285"></a>6 sed</h2>
<p>sed命令是利用脚本来处理文本文件,并且可以按照执行编辑文本文件。</p>
<pre><div class="hljs"><code class="lang-powershell">参数说明:
<span class="hljs-literal">-e</span><script>或<span class="hljs-literal">--expression</span>=<script> 以选项中指定的script来处理输入的文本文件。
<span class="hljs-operator">-f</span><script文件>或<span class="hljs-literal">--file</span>=<script文件> 以选项中指定的script文件来处理输入的文本文件。
<span class="hljs-literal">-h</span>或<span class="hljs-literal">--help</span> 显示帮助。
<span class="hljs-literal">-n</span>或<span class="hljs-literal">--quiet</span>或<span class="hljs-literal">--silent</span> 仅显示script处理后的结果。
<span class="hljs-literal">-V</span>或<span class="hljs-literal">--version</span> 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何东东;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed <span class="hljs-literal">-n</span> 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正则表达式!例如 <span class="hljs-number">1</span>,<span class="hljs-number">20</span>s/old/new/g 就是啦!
</code></div></pre>
<h3><a id="61__304"></a>6.1 查、删除、替换、增加、批量操作</h3>
<p>注:这里<code>nl</code>与<code>cat</code>效果相同</p>
<h4><a id="611__308"></a>6.1.1 查</h4>
<p>实例:查询第2行记录</p>
<pre><div class="hljs"><code class="lang-powershell">sed <span class="hljs-literal">-n</span> <span class="hljs-string">'2p'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/77bdeed2688f97e92ca5ea3bd8b0a45d.png" alt="image.png" /></p>
<p>实例:查询2~4行</p>
<pre><div class="hljs"><code class="lang-powershell">sed <span class="hljs-literal">-n</span> <span class="hljs-string">'2,4p'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/275b39edddd2825780d3ccbf3fe4d81b.png" alt="image.png" /></p>
<h4><a id="612__325"></a>6.1.2 增加</h4>
<p>实例:在第二行前 插入 ccc,并标准输出</p>
<pre><div class="hljs"><code class="lang-powershell">nl student.txt | sed <span class="hljs-string">'2i ccc'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/7b9bb8067a20dffb23353916c4ce9a22.png" alt="image.png" /></p>
<p>实例:在第二行后 插入 ccc,并标准输出</p>
<pre><div class="hljs"><code class="lang-powershell">nl student.txt | sed <span class="hljs-string">'2a ccc'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/b0401900a70435a2b7ef4651692d76a4.png" alt="image.png" /></p>
<h4><a id="613__342"></a>6.1.3 删除</h4>
<p>实例:删除3~4行,并标准输出</p>
<pre><div class="hljs"><code class="lang-powershell">nl student.txt | sed <span class="hljs-string">'3,4d'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e3f05501084a868d208a0a01b4f2ae09.png" alt="image.png" /></p>
<p>实例:删除第3~最后一行,并标准输出</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | sed <span class="hljs-string">'3,$d'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/7ad0b9899d315e1ea93b702b40af59f0.png" alt="image.png" /></p>
<h4><a id="614__359"></a>6.1.4 替换</h4>
<h5><a id="6141_e__360"></a>6.1.4.1 -e 不修改源文件</h5>
<pre><div class="hljs"><code class="lang-powershell">id name name2 score
<span class="hljs-number">1</span> cc cc <span class="hljs-number">100</span>
<span class="hljs-number">2</span> aa my <span class="hljs-number">99</span>
<span class="hljs-number">3</span> bb by <span class="hljs-number">92</span>
<span class="hljs-number">4</span> cc na <span class="hljs-number">96</span>
<span class="hljs-number">5</span> yy dd <span class="hljs-number">98</span>
</code></div></pre>
<p>语法:<code>sed s/被替换的字符串/新字符串/g</code></p>
<p>实例1:将每行第一次出现的 <code>cc</code> 替换为<code>导演</code>,并标准输出</p>
<pre><div class="hljs"><code class="lang-powershell">sed <span class="hljs-literal">-e</span> <span class="hljs-string">'s/cc/导演/'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/cb555e6e381c04442fd9909605f7033a.png" alt="image.png" /></p>
<p>实例2:基于实例1,替换所有符合条件的</p>
<pre><div class="hljs"><code class="lang-powershell">sed <span class="hljs-literal">-e</span> <span class="hljs-string">'s/cc/导演/g'</span> student.txt
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/b0d94bbe669f3809c0ffb3c5580b4f54.png" alt="image.png" /></p>
<h5><a id="6142_i__388"></a>6.1.4.2 -i 修改源文件</h5>
<p>用法同<code>-e</code>,区别在于是否修改源文件。</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-comment"># 将每行第一次出现的 cc 替换为导演</span>
sed <span class="hljs-literal">-e</span> <span class="hljs-string">'s/cc/导演/'</span> student.txt
<span class="hljs-comment"># 将所有的 cc 替换为导演</span>
sed <span class="hljs-literal">-e</span> <span class="hljs-string">'s/cc/导演/g'</span> student.txt
</code></div></pre>
<h5><a id="6143__398"></a>6.1.4.3 范围替换</h5>
<p>实例:将 2~5行替换为空</p>
<pre><div class="hljs"><code class="lang-powershell">nl student.txt | sed <span class="hljs-string">'2,5c 空空空'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e5a46afeecb4049200c79f905e132194.png" alt="image.png" /></p>
<h5><a id="6144__407"></a>6.1.4.4 批量操作</h5>
<p>将当前目录所有<code>stu</code>开头的文件进行操作</p>
<pre><div class="hljs"><code class="lang-powershell">sed <span class="hljs-literal">-i</span> <span class="hljs-string">'s/导演/cc/g'</span> stu*
</code></div></pre>
<h3><a id="62__413"></a>6.2 搜索</h3>
<pre><div class="hljs"><code class="lang-powershell">id name score
<span class="hljs-number">1</span> Charles <span class="hljs-number">100</span>
<span class="hljs-number">1</span> Charles_a <span class="hljs-number">99</span>
<span class="hljs-number">3</span> Lisa <span class="hljs-number">92</span>
<span class="hljs-number">2</span> Tom <span class="hljs-number">99</span>
<span class="hljs-number">3</span> Lisa_b <span class="hljs-number">95</span>
</code></div></pre>
<h4><a id="621__422"></a>6.2.1 仅搜索</h4>
<p>实例:搜索包含 <code>cc</code>的记录,并标准输出。</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | sed <span class="hljs-literal">-n</span> <span class="hljs-string">'/cc/p'</span>
</code></div></pre>
<h4><a id="622__427"></a>6.2.2 搜索并执行指令</h4>
<p>实例:搜索第一个匹配到的<code>cc</code>记录,并且将第一个<code>cc</code>替换为`导演,最后标准输出。</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | sed <span class="hljs-literal">-n</span> <span class="hljs-string">'/cc/{s/cc/导演/;p;q}'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/f1c61b4a931d47bb3329a79de7b238a7.png" alt="image.png" /></p>
<p>实例:搜索所有含有cc的记录,将第一个出现的<code>cc</code>替换为<code>导演</code>,并标准输出。</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">cat</span> student.txt | sed <span class="hljs-literal">-n</span> <span class="hljs-string">'/cc/{s/cc/导演/;p}'</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/993be60bc5968cfe9e131cbca2bee1ec.png" alt="image.png" /></p>
<h2><a id="7__444"></a>7 字符处理命令</h2>
<h3><a id="71_sort__445"></a>7.1 sort 排序</h3>
<p>语法:<code>sort [选项] 文件名</code></p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-literal">-b</span>: 忽略每行前面的空格字符
<span class="hljs-literal">-c</span>: 检查文件是否已经按照顺序排序
<span class="hljs-literal">-d</span>: 处理英文字母、数字及空格字符外,忽略其他的字符
<span class="hljs-operator">-f</span>: 忽略大小写
<span class="hljs-literal">-i</span>: 排序时,除了<span class="hljs-number">040</span>至<span class="hljs-number">176</span>之间的ASCII字符外,忽略其他的字符。
<span class="hljs-literal">-n</span>: 以数值型进行排序,默认使用字符串型排序
<span class="hljs-literal">-r</span>: 反向排序
<span class="hljs-literal">-u</span>: 删除重复行。就是uniq命令
<span class="hljs-literal">-t</span>: 指定分隔符,默认是分隔符是制表符
<span class="hljs-literal">-k</span> n[,<span class="hljs-type">m</span>]: ―按照指定的字段范围排序。从第n字段开始,m字段结束(默认到行尾)
</code></div></pre>
<h3><a id="72_uniq__462"></a>7.2 uniq 取消重复行</h3>
<p>语法:<code>uniq [选项] 文件名</code></p>
<p><code>-i</code>:忽略大小写</p>
<p>实例</p>
<pre><div class="hljs"><code class="lang-powershell"><span class="hljs-built_in">sort</span> <span class="hljs-literal">-n</span> student.txt | uniq
</code></div></pre>
<h3><a id="73_wc__472"></a>7.3 wc 统计命令</h3>
<p>语法:<code>wc [选项] 文件名</code></p>
<pre><div class="hljs"><code class="lang-powershell">选项:
<span class="hljs-literal">-l</span>:只统计行数
<span class="hljs-literal">-w</span>:只统计单词数
<span class="hljs-literal">-m</span>:只统计字符数
</code></div></pre>
<p>统计:student.txt</p>
<pre><div class="hljs"><code class="lang-powershell">[<span class="hljs-type">root</span>@<span class="hljs-type">master</span> <span class="hljs-type">shell</span>]<span class="hljs-comment"># wc student.txt </span>
<span class="hljs-number">6</span> <span class="hljs-number">24</span> <span class="hljs-number">76</span> student.txt
</code></div></pre>
<p>行数为6、单词数24、字节数76</p>

评论区