单机版 hadoop 云平台(伪分布式)搭建 统计单词
有勇气的牛排
1113
大数据
2022-07-07 11:28:44
1.首先需要配置java环境
CentOS安装java jdk教程
2.上传hadoop到/usr/local目录 并解压
cd /usr/local
ls
linux上传下载文件教程

3.配置hadoop环境目录
vim /etc/profile
#java environment
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=/usr/local/jdk1.8.0_151/jre
#export PATH=$PATH:/usr/local/jdk1.8.0_151/bin
export CLASSPATH=./:$JAVA_HOME/lib:$JRE_HOME/lib
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop-2.8.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
4.在hadoop配置文件 配置java jdk
vim /usr/local/hadoop-2.8.4/etc/hadoop/hadoop-env.sh
source /usr/local/hadoop-2.8.4/etc/hadoop/hadoop-env.sh
# The java implementation to use.
export JRE_HOME=/usr/local/jdk1.8.0_151
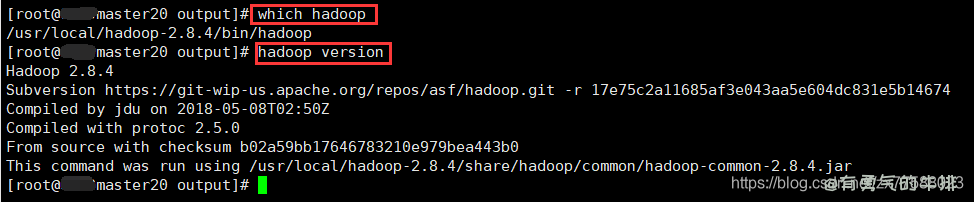
5.查看
which hadoop
hadoop version
6.统计单词
这里统计的是 /root/input/a.txt 文件,并且将结果存放到 /root/output 目录
hadoop jar /usr/local/hadoop-2.8.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /root/input/a.txt /root/output
7.查看结果
cd /root/output

<h2><a id="1java_0"></a>1.首先需要配置java环境</h2>
<p><a href="https://www.couragesteak.com/category/190" target="_blank">CentOS安装java jdk教程</a></p>
<h2><a id="2hadoopusrlocal__4"></a>2.上传hadoop到/usr/local目录 并解压</h2>
<pre><div class="hljs"><code class="lang-shell">cd /usr/local
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">ls
</code></div></pre>
<p><a href="https://www.couragesteak.com/article/199" target="_blank">linux上传下载文件教程</a></p>
<p><img src="https://www.couragesteak.com/tcos/article/cc382bfb46f8970f1c907130ac287254.png" alt="20201016000634531.png" /></p>
<h2><a id="3hadoop_19"></a>3.配置hadoop环境目录</h2>
<pre><div class="hljs"><code class="lang-shell">vim /etc/profile
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta">#</span><span class="language-bash">java environment</span>
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=/usr/local/jdk1.8.0_151/jre
<span class="hljs-meta">#</span><span class="language-bash"><span class="hljs-built_in">export</span> PATH=<span class="hljs-variable">$PATH</span>:/usr/local/jdk1.8.0_151/bin</span>
export CLASSPATH=./:$JAVA_HOME/lib:$JRE_HOME/lib
<span class="hljs-meta">
#</span><span class="language-bash">hadoop environment</span>
export HADOOP_HOME=/usr/local/hadoop-2.8.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
</code></div></pre>
<h2><a id="4hadoop_java_jdk_37"></a>4.在hadoop配置文件 配置java jdk</h2>
<pre><div class="hljs"><code class="lang-shell">vim /usr/local/hadoop-2.8.4/etc/hadoop/hadoop-env.sh
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">source /usr/local/hadoop-2.8.4/etc/hadoop/hadoop-env.sh
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">The java implementation to use.</span>
export JRE_HOME=/usr/local/jdk1.8.0_151
</code></div></pre>
<h2><a id="5_52"></a>5.查看</h2>
<pre><div class="hljs"><code class="lang-shell">which hadoop
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">hadoop version
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/d72c32f7632044d1ea3d7e1a1567eabf.png" alt="hadoop version" /></p>
<h2><a id="6_65"></a>6.统计单词</h2>
<p>这里统计的是 /root/input/a.txt 文件,并且将结果存放到 /root/output 目录</p>
<pre><code class="lang-powershell">hadoop jar /usr/local/hadoop-2.8.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /root/input/a.txt /root/output
</code></pre>
<h2><a id="7_73"></a>7.查看结果</h2>
<pre><code class="lang-powershell">cd /root/output
</code></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e1a9db34de8706661f5815ec9c8db8cf.png" alt="20201016000451452.png" /></p>

评论区