hadoop程序开发(Java)
有勇气的牛排
956
大数据
2022-12-04 17:26:04
1、创建maven项目
如果不懂配置maven请点击:传送门

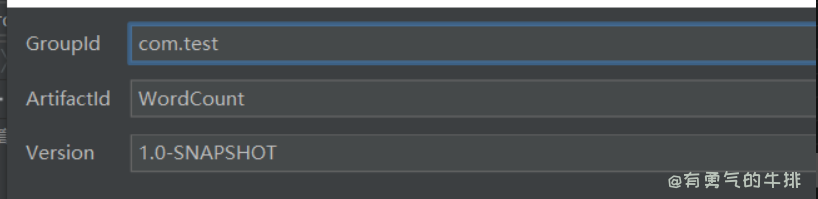
2、在pom.xml写入架包配置文件
<dependencies>
<!-- https:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
</dependencies>
3、创建源程序
src–>main–>java–>com–>test–>WordCount.java
WordCount.java
/ **
*通过一项授权给Apache Software Foundation(ASF)
*或更多贡献者许可协议。 查看公告文件
*随本作品分发以获取更多信息
*关于版权拥有权。 ASF许可此文件
*根据Apache许可2.0版(以下简称“
* “执照”); 除非合规,否则您不得使用此文件
*带许可证。 您可以在以下位置获得许可的副本:
*
* http:
*
*除非适用法律要求或书面同意,否则软件
*根据许可协议分发的内容是按“原样”分发的,
*不作任何明示或暗示的保证或条件。
*有关特定语言的管理权限,请参阅许可证
*许可中的限制。
* /
package com.xxx;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool {
public static class MapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
static int printUsage() {
System.out.println("wordcount [-m <maps>] [-r <reduces>] <input> <output>");
ToolRunner.printGenericCommandUsage(System.out);
return -1;
}
public int run(String[] args) throws Exception {
JobConf conf = new JobConf(getConf(), WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
List<String> other_args = new ArrayList<String>();
for(int i=0; i < args.length; ++i) {
try {
if ("-m".equals(args[i])) {
conf.setNumMapTasks(Integer.parseInt(args[++i]));
} else if ("-r".equals(args[i])) {
conf.setNumReduceTasks(Integer.parseInt(args[++i]));
} else {
other_args.add(args[i]);
}
} catch (NumberFormatException except) {
System.out.println("ERROR: Integer expected instead of " + args[i]);
return printUsage();
} catch (ArrayIndexOutOfBoundsException except) {
System.out.println("ERROR: Required parameter missing from " +
args[i-1]);
return printUsage();
}
}
if (other_args.size() != 2) {
System.out.println("ERROR: Wrong number of parameters: " +
other_args.size() + " instead of 2.");
return printUsage();
}
FileInputFormat.setInputPaths(conf, other_args.get(0));
FileOutputFormat.setOutputPath(conf, new Path(other_args.get(1)));
JobClient.runJob(conf);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new WordCount(), args);
System.exit(res);
}
}
4、将WordCount.java 打包为jar文件
(1)基本配置

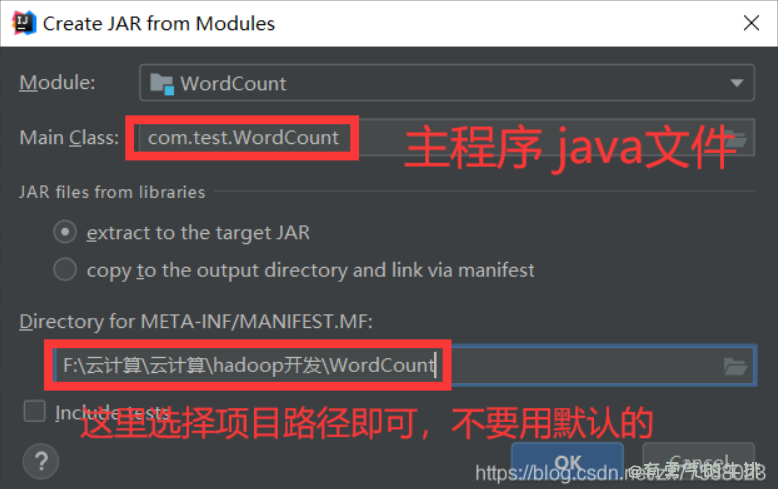
选择完后 Apply–>ok
(2)开始打包
Build–>Build Artifacts–> XXX.jar–> Build

(3)查看生成的jar文件
在文件夹 out–>artifacts–>WordCount_jar里面
5、运行
我这里将WordCount.jar 上传到 /usr/local/hadoop-jar 目录下了
运行命令
重要:程序名前一定要写 包名 这里是 com.test
yarn jar /usr/local/hadoop-jar/WordCount.jar com.test.WordCount /input/word.txt /output/01
6、结束
示例结束,如果想开发其他程序,可以自己另外编写java 文件,打包上传运行即可。
如有转载请标明出处,支持原创。
<h2><a id="1maven_0"></a>1、创建maven项目</h2>
<p>如果不懂配置maven请点击:<a href="https://blog.csdn.net/zx77588023/article/details/109126950" target="_blank">传送门</a></p>
<p><img src="https://www.couragesteak.com/tcos/article/31a8fe4991d877d73d9d7a5ba6f69554.png" alt="image.png" /></p>
<p><img src="https://www.couragesteak.com/tcos/article/0bad02ecc6c59d87c1e7d1255a4ab2e4.png" alt="image.png" /></p>
<h2><a id="2pomxml_8"></a>2、在pom.xml写入架包配置文件</h2>
<pre><div class="hljs"><code class="lang-java"><dependencies>
<!-- https:<span class="hljs-comment">//mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common --></span>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version><span class="hljs-number">2.8</span><span class="hljs-number">.4</span></version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version><span class="hljs-number">2.8</span><span class="hljs-number">.4</span></version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version><span class="hljs-number">2.8</span><span class="hljs-number">.4</span></version>
</dependency>
</dependencies>
</code></div></pre>
<h2><a id="3_36"></a>3、创建源程序</h2>
<p>src–>main–>java–>com–>test–>WordCount.java</p>
<p><img src="https://www.couragesteak.com/tcos/article/782ab2d20395aa18951587d11e412f1f.png" alt="image.png" /></p>
<p>WordCount.java</p>
<pre><div class="hljs"><code class="lang-java">/ **
*通过一项授权给Apache Software Foundation(ASF)
*或更多贡献者许可协议。 查看公告文件
*随本作品分发以获取更多信息
*关于版权拥有权。 ASF许可此文件
*根据Apache许可<span class="hljs-number">2.0</span>版(以下简称“
* “执照”); 除非合规,否则您不得使用此文件
*带许可证。 您可以在以下位置获得许可的副本:
*
* http:<span class="hljs-comment">//www.apache.org/licenses/LICENSE-2.0</span>
*
*除非适用法律要求或书面同意,否则软件
*根据许可协议分发的内容是按“原样”分发的,
*不作任何明示或暗示的保证或条件。
*有关特定语言的管理权限,请参阅许可证
*许可中的限制。
* /
<span class="hljs-keyword">package</span> com.xxx;
<span class="hljs-keyword">import</span> java.io.IOException;
<span class="hljs-keyword">import</span> java.util.ArrayList;
<span class="hljs-keyword">import</span> java.util.Iterator;
<span class="hljs-keyword">import</span> java.util.List;
<span class="hljs-keyword">import</span> java.util.StringTokenizer;
<span class="hljs-keyword">import</span> org.apache.hadoop.conf.Configuration;
<span class="hljs-keyword">import</span> org.apache.hadoop.conf.Configured;
<span class="hljs-keyword">import</span> org.apache.hadoop.fs.Path;
<span class="hljs-keyword">import</span> org.apache.hadoop.io.IntWritable;
<span class="hljs-keyword">import</span> org.apache.hadoop.io.LongWritable;
<span class="hljs-keyword">import</span> org.apache.hadoop.io.Text;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.FileInputFormat;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.FileOutputFormat;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.JobClient;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.JobConf;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.MapReduceBase;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.Mapper;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.OutputCollector;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.Reducer;
<span class="hljs-keyword">import</span> org.apache.hadoop.mapred.Reporter;
<span class="hljs-keyword">import</span> org.apache.hadoop.util.Tool;
<span class="hljs-keyword">import</span> org.apache.hadoop.util.ToolRunner;
<span class="hljs-comment">/**
* 这是一个示例Hadoop Map / Reduce应用程序。
* 读取文本输入文件,将每一行分解为单词
* 并计数。 输出是单词的本地排序列表,并且
* 计算它们发生的频率。
*
* 运行:bin / hadoop jar build / hadoop-examples.jar wordcount
* [-m <i>地图</ i>] [-r <i>减少</ i>] <i>目录内</ i> <i>目录外</ i>
*/</span>
<span class="hljs-keyword">public</span> <span class="hljs-keyword">class</span> <span class="hljs-title class_">WordCount</span> <span class="hljs-keyword">extends</span> <span class="hljs-title class_">Configured</span> <span class="hljs-keyword">implements</span> <span class="hljs-title class_">Tool</span> {
<span class="hljs-comment">/**
* 计算每一行中的单词。
* 于输入的每一行,将其分解为单词并将其作为
* <b>单词</ b>,<b> 1 </ b>)。
*/</span>
<span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">class</span> <span class="hljs-title class_">MapClass</span> <span class="hljs-keyword">extends</span> <span class="hljs-title class_">MapReduceBase</span>
<span class="hljs-keyword">implements</span> <span class="hljs-title class_">Mapper</span><LongWritable, Text, Text, IntWritable> {
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">static</span> <span class="hljs-type">IntWritable</span> <span class="hljs-variable">one</span> <span class="hljs-operator">=</span> <span class="hljs-keyword">new</span> <span class="hljs-title class_">IntWritable</span>(<span class="hljs-number">1</span>);
<span class="hljs-keyword">private</span> <span class="hljs-type">Text</span> <span class="hljs-variable">word</span> <span class="hljs-operator">=</span> <span class="hljs-keyword">new</span> <span class="hljs-title class_">Text</span>();
<span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title function_">map</span><span class="hljs-params">(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter)</span> <span class="hljs-keyword">throws</span> IOException {
<span class="hljs-type">String</span> <span class="hljs-variable">line</span> <span class="hljs-operator">=</span> value.toString();
<span class="hljs-type">StringTokenizer</span> <span class="hljs-variable">itr</span> <span class="hljs-operator">=</span> <span class="hljs-keyword">new</span> <span class="hljs-title class_">StringTokenizer</span>(line);
<span class="hljs-keyword">while</span> (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
<span class="hljs-comment">/**
* 一个reducer类,该类仅发出输入值的总和。
*/</span>
<span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">class</span> <span class="hljs-title class_">Reduce</span> <span class="hljs-keyword">extends</span> <span class="hljs-title class_">MapReduceBase</span>
<span class="hljs-keyword">implements</span> <span class="hljs-title class_">Reducer</span><Text, IntWritable, Text, IntWritable> {
<span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title function_">reduce</span><span class="hljs-params">(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter)</span> <span class="hljs-keyword">throws</span> IOException {
<span class="hljs-type">int</span> <span class="hljs-variable">sum</span> <span class="hljs-operator">=</span> <span class="hljs-number">0</span>;
<span class="hljs-keyword">while</span> (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, <span class="hljs-keyword">new</span> <span class="hljs-title class_">IntWritable</span>(sum));
}
}
<span class="hljs-keyword">static</span> <span class="hljs-type">int</span> <span class="hljs-title function_">printUsage</span><span class="hljs-params">()</span> {
System.out.println(<span class="hljs-string">"wordcount [-m <maps>] [-r <reduces>] <input> <output>"</span>);
ToolRunner.printGenericCommandUsage(System.out);
<span class="hljs-keyword">return</span> -<span class="hljs-number">1</span>;
}
<span class="hljs-comment">/**
* 字数映射/减少程序的主要驱动程序。
* 调用此方法以提交地图/缩小作业。
* <span class="hljs-doctag">@throws</span> When there is communication problems with the job tracker.
*/</span>
<span class="hljs-keyword">public</span> <span class="hljs-type">int</span> <span class="hljs-title function_">run</span><span class="hljs-params">(String[] args)</span> <span class="hljs-keyword">throws</span> Exception {
<span class="hljs-type">JobConf</span> <span class="hljs-variable">conf</span> <span class="hljs-operator">=</span> <span class="hljs-keyword">new</span> <span class="hljs-title class_">JobConf</span>(getConf(), WordCount.class);
conf.setJobName(<span class="hljs-string">"wordcount"</span>);
<span class="hljs-comment">// the keys are words (strings)</span>
conf.setOutputKeyClass(Text.class);
<span class="hljs-comment">// the values are counts (ints)</span>
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
List<String> other_args = <span class="hljs-keyword">new</span> <span class="hljs-title class_">ArrayList</span><String>();
<span class="hljs-keyword">for</span>(<span class="hljs-type">int</span> i=<span class="hljs-number">0</span>; i < args.length; ++i) {
<span class="hljs-keyword">try</span> {
<span class="hljs-keyword">if</span> (<span class="hljs-string">"-m"</span>.equals(args[i])) {
conf.setNumMapTasks(Integer.parseInt(args[++i]));
} <span class="hljs-keyword">else</span> <span class="hljs-keyword">if</span> (<span class="hljs-string">"-r"</span>.equals(args[i])) {
conf.setNumReduceTasks(Integer.parseInt(args[++i]));
} <span class="hljs-keyword">else</span> {
other_args.add(args[i]);
}
} <span class="hljs-keyword">catch</span> (NumberFormatException except) {
System.out.println(<span class="hljs-string">"ERROR: Integer expected instead of "</span> + args[i]);
<span class="hljs-keyword">return</span> printUsage();
} <span class="hljs-keyword">catch</span> (ArrayIndexOutOfBoundsException except) {
System.out.println(<span class="hljs-string">"ERROR: Required parameter missing from "</span> +
args[i-<span class="hljs-number">1</span>]);
<span class="hljs-keyword">return</span> printUsage();
}
}
<span class="hljs-comment">// Make sure there are exactly 2 parameters left.</span>
<span class="hljs-keyword">if</span> (other_args.size() != <span class="hljs-number">2</span>) {
System.out.println(<span class="hljs-string">"ERROR: Wrong number of parameters: "</span> +
other_args.size() + <span class="hljs-string">" instead of 2."</span>);
<span class="hljs-keyword">return</span> printUsage();
}
FileInputFormat.setInputPaths(conf, other_args.get(<span class="hljs-number">0</span>));
FileOutputFormat.setOutputPath(conf, <span class="hljs-keyword">new</span> <span class="hljs-title class_">Path</span>(other_args.get(<span class="hljs-number">1</span>)));
JobClient.runJob(conf);
<span class="hljs-keyword">return</span> <span class="hljs-number">0</span>;
}
<span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">void</span> <span class="hljs-title function_">main</span><span class="hljs-params">(String[] args)</span> <span class="hljs-keyword">throws</span> Exception {
<span class="hljs-type">int</span> <span class="hljs-variable">res</span> <span class="hljs-operator">=</span> ToolRunner.run(<span class="hljs-keyword">new</span> <span class="hljs-title class_">Configuration</span>(), <span class="hljs-keyword">new</span> <span class="hljs-title class_">WordCount</span>(), args);
System.exit(res);
}
}
</code></div></pre>
<h2><a id="4WordCountjava_jar_204"></a>4、将WordCount.java 打包为jar文件</h2>
<h3><a id="1_206"></a>(1)基本配置</h3>
<p><img src="https://www.couragesteak.com/tcos/article/ff0f2244cb9e579f5fd70fc9c068fbf5.png" alt="image.png" /></p>
<p><img src="https://www.couragesteak.com/tcos/article/43c2573c024a6863ffecc11980208580.png" alt="image.png" /></p>
<p>选择完后 Apply–>ok</p>
<h3><a id="2_215"></a>(2)开始打包</h3>
<p>Build–>Build Artifacts–> XXX.jar–> Build</p>
<p><img src="https://www.couragesteak.com/tcos/article/50caf40b0e017739c491c13f3e32f64c.png" alt="image.png" /></p>
<h3><a id="3jar_221"></a>(3)查看生成的jar文件</h3>
<p>在文件夹 out–>artifacts–>WordCount_jar里面</p>
<h2><a id="5_226"></a>5、运行</h2>
<p>我这里将WordCount.jar 上传到 /usr/local/hadoop-jar 目录下了<br />
运行命令</p>
<p>重要:程序名前一定要写 包名 这里是 com.test</p>
<pre><div class="hljs"><code class="lang-shell">yarn jar /usr/local/hadoop-jar/WordCount.jar com.test.WordCount /input/word.txt /output/01
</code></div></pre>
<h2><a id="6_237"></a>6、结束</h2>
<p>示例结束,如果想开发其他程序,可以自己另外编写java 文件,打包上传运行即可。<br />
如有转载请标明出处,支持原创。</p>

评论区