哈喽,大家好,我是有勇气的牛排(全网同名)🐮🐮🐮
有问题的小伙伴欢迎在文末评论,点赞、收藏是对我最大的支持!!!。
文章目录
1 Redis 十大数据类型
Redis中数据是 key-value 形式存储。一般key被设定为字符串。key为字符串类型,
value有如下类型:
- redis字符串(String)
- redis列表(List)
- redis哈希表(Hash)
- redis集合(Set)
- redis有序集合(ZSet)
- redis地理空间(GEO)
- reids基数统计(HyperLogLog)
- reids位图(bitmap)
- redis位域(bitfield)
- redis流(Stream)
2 库操作
1、切换数据库
select 库
2、查看当前数据库的key数量
dbsize
3、清空当前库
flushdb
4、通杀全部库
flushall
帮助:hele @数据类型
3 Redis的Key
- 一般成功返回1,失败返回0
- 命令不区分大小写,而key区分大小写
3.1 keys *
查看所有key
keys *
h?llo 匹配 hello, hallo 和 hxllo
h*llo 匹配 hllo 和 heeeello
h[ae]llo 匹配 hello and hallo, 不匹配 hillo
h[^e]llo 匹配 hallo, hbllo, … 不匹配 hello
h[a-b]llo 匹配 hallo 和 hbllo
3.2 dbsize
查看当前数据库key的数量
3.2 exist key 判断key是否存在
语法:exist <key>
set name 有勇气的牛排
exists name
exists name1

3.3 type key 查看key类型
语法:type <key>

3.4 expire key 为key设置过期时间
单位秒
语法:expire <key> <秒数>
set name 有勇气的牛排
expire name 5
3.5 ttl key 查看key过过期时间
语法:ttl <key>
-1:代表永不过期。
-2:代表已过期

3.6 move key 移动key到其他库
语法:move key [0~15]
# 移动k1到db2
move k1 2
3.7 del key 删除指定key数据
1、语法:del <key>(多个key,用空格隔开)
返回值:被删除key的数量。

3.8 unlink key 异步删除key
2、语法:unlink <key>(多个key,用空格隔开)
不同于del的是,unlink仅将keysoace从元数据中删除,真正的删除在后续的异步操作完成。
set name 有勇气的牛排
unlink name
4 Redis字符串(String)
String是Redis最基本的数据类型,最大到512M,是二进制安全的。意味着Redis的String可以包含任何数据。比如jpg图片或者序列化的对象。
String的数据结构为简单东岱字符串(Simple Dynamic String,缩写SDS),是可以修改的字符串,内部结构实现上类似于JAVA的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
一般内部会给字符串分配大于字符串的长度,当字符串长度小于1M时,扩容加倍增长;当大于1M时,则只会多扩1M空间,最大512M。
4.1 set 命令
1、set
语法:set <key> <value> <EX> <PX>
属性:重复set,则覆盖原有value
key:键
value:值
ex:超时秒数
PX:超时毫秒数
例如:key=name、value=cs,并且5秒过期
set name cs 5
4.2 get 命令
定义:获取key的value值
语法:get <key>

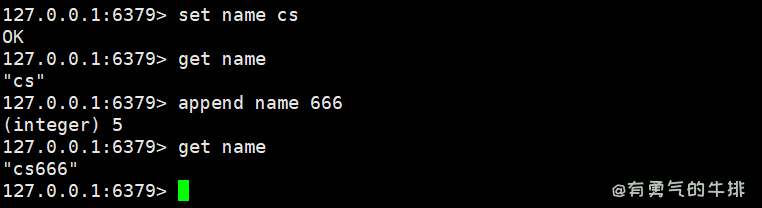
4.3 append 字符串内容追加
定义:获取字符串内容,并且内容追加
语法:append <key> <value>
4.4 strlen 获得值的长度
语法:stelen <key>
strlen name
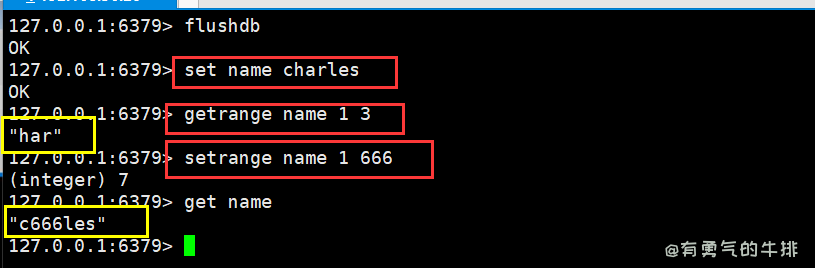
4.5 getrange与setrange 区间范围值
语法:
getrange <key> <起始位置> <结束位置>
setrange <key> <起始位置>(会按位数覆盖)
4.6 数值自增&自减
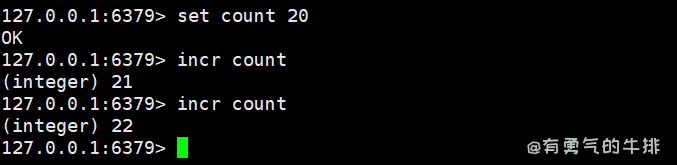
4.6.1 incr、decr
定义:将key中的的数值+1或-1,必须为数值类型,若为空,则默认为1。
场景:可以做流量控制、网页访问次数统计等,具有原子性。
语法:incr <key>、decr <key>
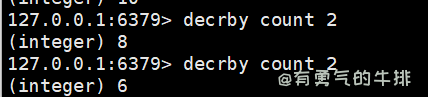
4.6.2 incrby与decrby指定步长
语法:incrby <key> <步长>、decrby <key> <步长>
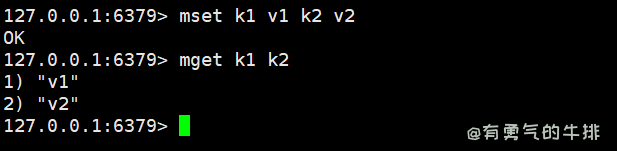
4.7 mset、msetnx与mget 读/写多个k-v
语法:
mset <key1> <value1> <key2> <value2>
msetnx <key1> <value1> <key2> <value2>
mget <key1> <key2>
注:msetnx当且仅当所有key不存在才能成功,只要一个失败,则都失败(原子性)。
4.8 getset 新旧址替换
定义:获取旧值,并且替换为新值。
语法:getset <key> <value>

4.9 分布式锁
4.9.1 setnx
定义:key不存在时才能成功设置值
语法:stelen <key>
4.9.2 setex
定义:写键值对,附加过期时间
语法:setex <key> <过期时间> <value>
5 Redis列表List
Redis列表是简单的字符串列表,即一键多值,按照插入顺序排序,可以插到列表头部或者尾部。
其底层实际是由双向列表实现,对两端的操作性能很高,通过索引下标操作中间节点的性能较差。
数据结构
List
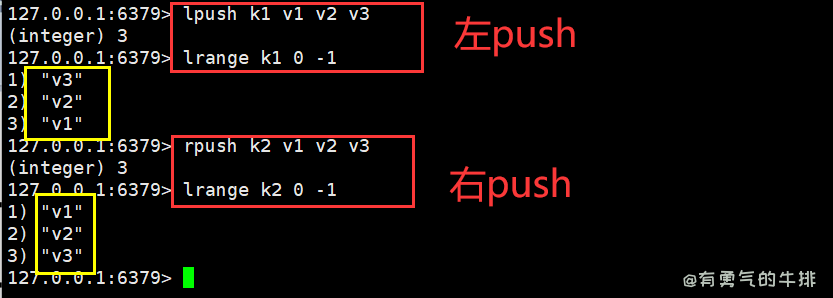
5.1 lpush与rpush
定义:从左边/右边插入1个或多个值。
lpush <key> <v1> <v2> ... <vn>
rpush <key> <v1> <v2> ... <vn>
5.2 lpop与rpop
定义:从左边/右边 吐出一个值。(取出来就没有了哦)
语法:
lpop <key> <count>
rpop <key> <count>

5.4 rpoplpush 右出左进
定义:右边pop一个值,push到左边。
语法:rpoplpush <key1> <key2>
5.4 lrange查询
定义:安装索引下表查询元素(从左到右)
lrange <key> <start> <stop>
查询所有:
lrange <key> 0 -1
5.5 其他
# 1 按照索引下标获得元素(从做到右)
语法:lindex <key> <index>
# 2 获取列表长度
语法:llen <key>
# 3 删除左边n个value
语法:lrem <key> <n> <value>
# 4 插入新值
linsert <key> index before/after
# 5 lset
5.6 应用场景(公众号消息订阅)
微信公众号订阅消息
原理:创作者发布文章后,就会将文章id写入到订阅者的List中。
6 Redis 哈希(Hash)
- Redis hash是一个键值对集合。
- Redis hash是一个string类型的files和value的映射表,hash特别适合用于存储对象。
- kv模式不变,但v是一个键值对。
数据结构
Hash类型对应的数据结构有两种:
- ziplist(压缩列表)
- hashtable(哈希表)
当field-value 长度较短且个数较少时,使用ziplist,否则使用hashtable。
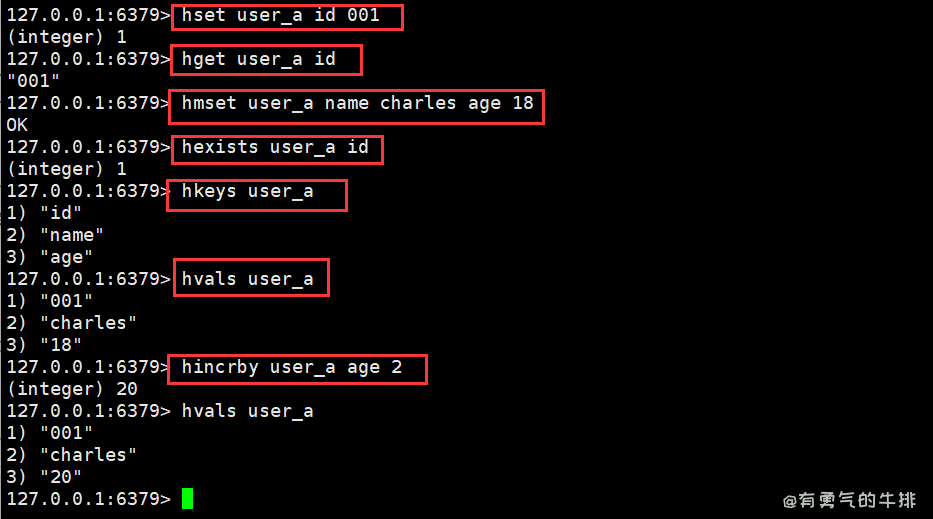
6.1 hset、hget
给集合key的filed复制value
hset <key> <filed> <value>
hget <key> <filed>
hset user:cs age 20
hget user:cs age
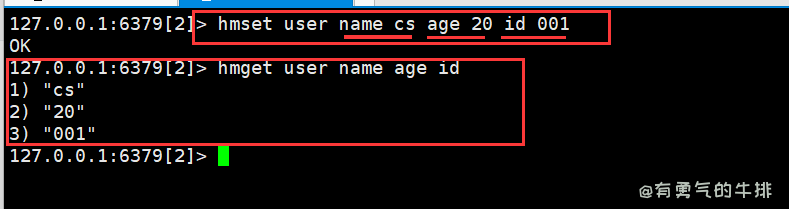
6.2 hmset、hmget批量设置值
hmset <key1> <filed1> <value1> <filed2> <value2> ...
hmset user name cs age 20 id 001
hmget user name age id
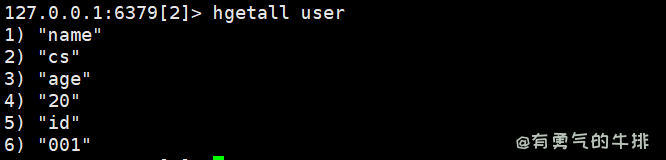
6.3 hgetall、hlen、hdel
hgetall <key>:获取所有子键
hlen <key>:获取键长度
hdel <key>:删除键
6.4 hexists、hkeys、hvals
hexists <key1> <filed>: 查看哈希集合key中filed是否存在
hkeys <key>: 列出哈希集合key中所有field
hvals <key>: 列出哈希集合key的所有value
6.5 hincrby 数值增减
为哈希集合key的field的值加减指定值
hincrby <key> <filed> <increment>:
6.6 hsetnx 不存在新增(分布式)
新增哈希集合key的filed域,当且仅当filed不存在
hsetnx <key> <field> <value>
6.7 应用场景(购物车)
小公司可以用
例如:购物车中商品的数量
# 场景
bigkey smallkey value
用户id 商品id 商品属性(数量)
# 新增商品(001用户,加购2号商品,5个)
hset shopcar:user001 2 5
# 增加商品数量
hincrby shopcar:user001 2 1
# 加购商品总数量
hlen shopcar:user001
# 全部选择
hget shopcar:user001
7 Redis集合(Set)
Redis Set对外提供的功能与list类似,都提供的是列表功能,其特殊之处在于set可以自动排重,而且set提供了判断成员是否存在的接口,list是没有的。
Redis的set集合是string类型的无序集合,底层为一个value为null的hash表,故新增、删除、查询的复杂度都是 O(1),即查询时间不随数据量增减而改变。
数据结构
其数据结构由dict字典实现(字典由哈希表实现)
Java中的HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也一样,其内部使用hash结构,所有value指向同一个值。
7.1 sadd、smembers
1、将一个或多个member元素加入到集合key中,已经存在的member会被忽略。
sadd <key> <value1> <value2> ...
2、获取集合key的所有值
smembers <key>
7.2 sismember 判断值是否存在集合中
判断集合key,是否包含value值。
sismember <key> <value>
7.3 scard 获取集合元素个数
返回集合key的元素个数
scard <key>
7.4 srem 删除集合中指定元素
删除集合中的某个元素
srem <key> <value1> <value2> ...
7.6 spop 随机从集合pop值,且删除
随机从集合中吐出n个值(n可以不写,默认为1)
spop <key> <n>
7.7 srandmember 随机取值,不删除
随机从集合中取出n个值,但不从集合中删除
srandmember <key> <n>
7.8 smove 移动
将value从一个集合key1移动到集合key2中。
smove <key1> <key2> <value>
7.9 sinter、sunion 、sdiff 集合运算(交并差集)
获取两个集合的交集
sinter <ke1> <key2>
获取两个集合的并集
sunion <key1> <key2>
获取两个集合的差集
sdiff <key1> <key2>
7.10 应用场景(抽奖、共同好友、可能认识的人…)
抽奖
# 参与抽奖
sadd key 用户ID
# 显示多少人参数抽奖
scard key
# 随机选取n个中奖人
srandmember key 2 # 元素不删除
spop key 2 # 元素会删除(即不允许重复抽奖)
例如:朋友圈同赞朋友
# 新增点赞
sadd pub:msgID 点赞用户ID1 点赞用户ID2
# 取消点赞
srem pub:msgID 点赞用户ID
# 展现所有点赞用户
smembers pub:msgID
# 点赞用户数统计
scard pub:msgID
可能认识的人、猜你喜欢
# 原理:取差集
sdiff user1 user2
8 Redis有序结合 Zset(sorted set)
zset与set非常相似,是一个没有重复元素的字符串集合。
不通之处是有序集合的每个成员关联了一个评分(score),这个评分被用来按照从最低到最高分的方式排序集合中的成员。(评分可以被重复)
数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map(String, Double), 可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部元素会按照权重score进行排序,可以得到每个元素的名词,还可以通过score范围来获取元素列表。
zset底层使用了两个数据结构:
- hash,hash的作用是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到响应的score值。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
8.1 zadd 插入 元素+分数
1、将一个或多个member元素及score值加入到有序集key中
zadd <key> <score1> <value> <score2> <value2>
zadd cs 99 math 98 chinese 100 computer
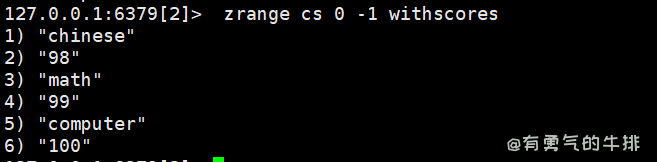
8.2 zrange、zrevrange
- zrange:安顺序取
- zrevrange:顺序反转
获取有序集合key中,下表在<start>-<stop>之间的元素
[WITHSOCRES]参数代表,分数也被返回。
zrange <key> <start> <stop> [WITHSOCRES]
取所有:
zrange cs 0 -1

带分数
zrange cs 0 -1 withscores
8.3 zrangebyscore
按score范围查(例如200->300之间),从小到大
zrangebyscore <key> 200 300 withscores
# 拿出99~100的科目 包含99
zrangebyscore cs 99 100 withscores
# 拿出99~100的科目 不包含99
zrangebyscore cs (99 100 withscores
# 拿出90~100的科目 前两个
zrangebyscore cs 90 100 withscores limit 0 2
8.4 zscore 获取元素的分数
zscore key member
zscore cs computer
8.5 zrem删除
删除指定元素
zrem <key> <value>
8.6 zincrby增加
zincrby <key> <increment> <value>
8.7 zcount 获得分数区间的元素个数
获得分数区间的元素个数
zcount <key> <min> <max>
8.8 zrank 获取下标
返回集合中的下标,从0开始
zrank <key> <value>
8.9 zmpop
# 弹出最小的
zmpop 1 cs min count 1
8.10 应用场景(按照销售情况排序商品)
定义商品销售排行榜(sorted set集合),key为good:sellsort,分数为商品销售数量
# 商品1001销量为9,商品1002销量为15
zadd goods: sellsort 9 1001 15 1002
# 有一个客户又买了2件1001
zincrby goods: sellsort 2 1001
# 求商品销量前10名(定时刷新获取)
zrange goods:sellsort 0 9 withscores
9 Redis位图(bitmap)
**定义:**由0和1状态表现的二进制位的bit数组
说明:
用String类型作为底层数据结构实现的一种统计二值状态的数据类型。
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成。每个二进制位都对应一个偏移量(我们称之为索引)。
Bitmap支持最大的位数为232位,它可以极大的节约存储空间,使用512M内存就可以存储多达42.9亿的字节信息(232=4294967296)
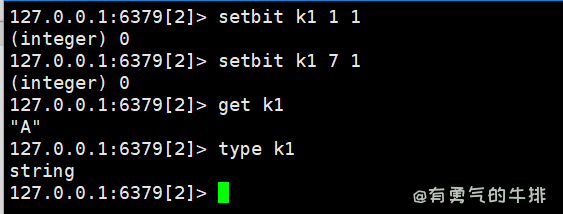
9.1 setbit、getbit
语法: setbit <key> offset value
# 第1、7天有签到
setbit k1 1 1
setbit k1 7 1
# 获取第6天签到情况
getbit k1 6 # 结果0
9.2 strlen 统计字节数占用多少
原理:这里8位为一组,不是字符串长度多少而占用几个字节,而是超过8位一组,byte再扩容。
语法:strlen <key>,(输出字节数)
9.3 bitcount 全部键里含有1的个数
语法:bitcount <key>
9.4 bitstop(统计登录次数)
查看那连续2天签到用户
# 映射用户
hset uid:map 0 uid_1
hset uid:map 1 uid_2
# 查看所有用户
hgetall uid:map
# 记录登录过得用户:
# 10号,0~3号用户登录过
setbit 20230310 0 1
setbit 20230310 1 1
setbit 20230310 2 1
setbit 20230310 3 1
# 11号,0、2号用户登录过
setbit 20230310 0 1
setbit 20230311 2 1
# 查看那20230311,0号用户有没有登录过
getbit 20230311 0
# 统计指定10、11号都登录的用户
bitop and haslogin 20230310 20230311
bitcount haslogin
9.5 应用场景(打卡、签到、广告点击…)
- 用户状态统计
- 用户是否登录过Y、N;比如每日签到送积分
- 电影、广告是否被点击播放过
- 打卡上下班,签到统计
10 Redis HyperLogLog 去重复统计功能的基数估计算法
定义:去重复统计功能的基数估计算法
基数:是一种数据集,去重复后的真实个数
缺点:有个标准误差在0.81%
在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算将近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
10.1 pfadd、pfcount、pfmerge 添加/统计/合并
# 模拟第1、2天的ip
pfadd ip01 1 1 2 2 3 4 5 6
pfadd ip02 8 8 9 9
# 统计ip数量
pfcount ip01 # 6个
pfcount ip02 # 2个
# 合并1、2两天的ip
pfmerge disresult ip01 ip02
pfcount disresult # 8个
10.2 应用场景(UV统计)
- 统计某个网站的UV、统计文章的UV
- 用户搜索网站关键词的数量
- 统计用户每天搜索不同词条个数
什么是UV:
- Unique Vistor:独立访客,一般理解为客户端IP
- 需要去重处理的情况,一个IP为一次
11 Redis地理空间(GEO)
- Redis在3.2版本以后增加了地理位置的处理
- 类型为zset
由于中文乱码,连接需要加参数
redis-cli -a 123456 --raw
百度接口(获取经纬度):https://api.map.baidu.com/lbsapi/getpoint/
天安门:116.404082,39.909187
泰山:117.094738,36.269893
11.1 geoadd 添加经纬度坐标
语法:geoadd key 经度 纬度 member
# 添加
geoadd city 116.404082 39.909187 "天安门" 117.094738 36.269893 "泰山"
# 查看
zrange city 0 -1
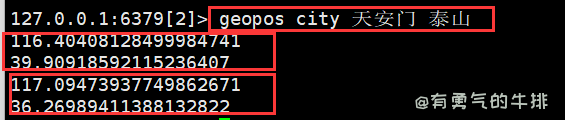
11.2 geopos 返回经纬度
语法:geopos <key> <member> [member ...]
geopos city 天安门 泰山
11.3 geohash 返回坐标hash表示
- geohash算法生成base32编码值
- 3维变2维变1维
语法:geohash <key > <member> [member ...]
geohash city 天安门 泰山

11.4 geodist 获取两个位置之间距离
语法:geodist <key > <member1> <member2>
单位:m、km、ft、mi
geodist city 天安门 泰山 km
11.5 georadius 以某个半径 查找附近 ***
定义:以给定的经纬度为中心,返回键包含的位置元素中,与中心的距离不超过给定最大距离的所有位置元素。
语法:``
georadius city 116.404082 39.909187 500 km withdist withcoord count 10 withhash desc
georadiusbymember city 天安门 500 km withdist withcoord count 10 withhash desc
12 Redis 流(Stream)
12.1 介绍
12.1.1 Stream流是什么
在Redis 5.0之前通过Redis实现消息队列,有两种方案:
- list实现消息队列(点对点模式)(简单实现)
- Pub/Sub
但是 发布订阅Pub/Sub模式有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息机会被丢弃,而且也没有ACK机制来保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。
因此新增了Steam实现了Redis版的消息中间件。
12.1.1 Stream流能干什么
实现消息队列、支持消息的持久化、支持自动生成全局唯一ID、支持ack确认消息的模式、支持消费组模式登,让消息队列更加的稳定和可靠。
这里建议使用专用的MQ,大厂不会采用。
13 Redis 位域(bitfield)
bitfield命令可以将一个Redis字符串看做是一个由二进制位组成的数组,并对这个数组中任意偏移进行访问。
参考地址:
https://www.bilibili.com/video/BV1YK411M7MG
https://www.bilibili.com/video/BV1Rv41177Af
https://www.bilibili.com/video/BV13R4y1v7sP(尚硅谷 阳哥)
<p><font face="楷体,华文行楷,隶书,黑体" color="red" size="4"><strong>哈喽,大家好,我是有勇气的牛排(全网同名)🐮🐮🐮</strong></font></p>
<p><font face="楷体,华文行楷,隶书,黑体" color="blue" size="4"><strong>有问题的小伙伴欢迎在文末评论,点赞、收藏是对我最大的支持!!!。</strong></font></p>
<p><h3>文章目录</h3><ul><ul><li><a href="#1_Redis__6">1 Redis 十大数据类型</a></li><li><a href="#2__22">2 库操作</a></li><li><a href="#3_RedisKey_54">3 Redis的Key</a></li><ul><li><a href="#31_keys__59">3.1 keys *</a></li><li><a href="#32_dbsize_73">3.2 dbsize</a></li><li><a href="#32_exist_key_key_77">3.2 exist key 判断key是否存在</a></li><li><a href="#33_type_key_key_89">3.3 type key 查看key类型</a></li><li><a href="#34_expire_key_key_97">3.4 expire key 为key设置过期时间</a></li><li><a href="#35_ttl_key_key_110">3.5 ttl key 查看key过过期时间</a></li><li><a href="#36_move_key_key_121">3.6 move key 移动key到其他库</a></li><li><a href="#37_del_key_key_132">3.7 del key 删除指定key数据</a></li><li><a href="#38_unlink_key_key_142">3.8 unlink key 异步删除key</a></li></ul><li><a href="#4_RedisString_161">4 Redis字符串(String)</a></li><ul><li><a href="#41_set__169">4.1 set 命令</a></li><li><a href="#42_get__189">4.2 get 命令</a></li><li><a href="#43_append__198">4.3 append 字符串内容追加</a></li><li><a href="#44_strlen__209">4.4 strlen 获得值的长度</a></li><li><a href="#45_getrangesetrange__217">4.5 getrange与setrange 区间范围值</a></li><li><a href="#46__227">4.6 数值自增&自减</a></li><ul><li><a href="#461_incrdecr_229">4.6.1 incr、decr</a></li><li><a href="#462_incrbydecrby_237">4.6.2 incrby与decrby指定步长</a></li></ul><li><a href="#47_msetmsetnxmget_kv_243">4.7 mset、msetnx与mget 读/写多个k-v</a></li><li><a href="#48_getset__258">4.8 getset 新旧址替换</a></li><li><a href="#49__268">4.9 分布式锁</a></li><ul><li><a href="#491_setnx_270">4.9.1 setnx</a></li><li><a href="#492_setex_276">4.9.2 setex</a></li></ul></ul><li><a href="#5_RedisList_284">5 Redis列表List</a></li><ul><li><a href="#51_lpushrpush_294">5.1 lpush与rpush</a></li><li><a href="#52_lpoprpop_304">5.2 lpop与rpop</a></li><li><a href="#54_rpoplpush__315">5.4 rpoplpush 右出左进</a></li><li><a href="#54_lrange_322">5.4 lrange查询</a></li><li><a href="#55__334">5.5 其他</a></li><li><a href="#56__352">5.6 应用场景(公众号消息订阅)</a></li></ul><li><a href="#6_Redis_Hash_362">6 Redis 哈希(Hash)</a></li><ul><li><a href="#61_hsethget_378">6.1 hset、hget</a></li><li><a href="#62_hmsethmget_390">6.2 hmset、hmget批量设置值</a></li><li><a href="#63_hgetallhlenhdel_402">6.3 hgetall、hlen、hdel</a></li><li><a href="#64_hexistshkeyshvals_412">6.4 hexists、hkeys、hvals</a></li><li><a href="#65_hincrby__420">6.5 hincrby 数值增减</a></li><li><a href="#66_hsetnx__428">6.6 hsetnx 不存在新增(分布式)</a></li><li><a href="#67__436">6.7 应用场景(购物车)</a></li></ul><li><a href="#7_RedisSet_458">7 Redis集合(Set)</a></li><ul><li><a href="#71_saddsmembers_476">7.1 sadd、smembers</a></li><li><a href="#72_sismember__487">7.2 sismember 判断值是否存在集合中</a></li><li><a href="#73_scard__495">7.3 scard 获取集合元素个数</a></li><li><a href="#74_srem__503">7.4 srem 删除集合中指定元素</a></li><li><a href="#76_spop_pop_511">7.6 spop 随机从集合pop值,且删除</a></li><li><a href="#77_srandmember__519">7.7 srandmember 随机取值,不删除</a></li><li><a href="#78_smove__527">7.8 smove 移动</a></li><li><a href="#79_sintersunion_sdiff__535">7.9 sinter、sunion 、sdiff 集合运算(交并差集)</a></li><li><a href="#710__551">7.10 应用场景(抽奖、共同好友、可能认识的人...)</a></li></ul><li><a href="#8_Redis_Zsetsorted_set_592">8 Redis有序结合 Zset(sorted set)</a></li><ul><li><a href="#81_zadd___609">8.1 zadd 插入 元素+分数</a></li><li><a href="#82_zrangezrevrange_623">8.2 zrange、zrevrange</a></li><li><a href="#83_zrangebyscore_652">8.3 zrangebyscore</a></li><li><a href="#84_zscore__670">8.4 zscore 获取元素的分数</a></li><li><a href="#85_zrem_680">8.5 zrem删除</a></li><li><a href="#86_zincrby_688">8.6 zincrby增加</a></li><li><a href="#87_zcount__694">8.7 zcount 获得分数区间的元素个数</a></li><li><a href="#88_zrank__702">8.8 zrank 获取下标</a></li><li><a href="#89_zmpop_712">8.9 zmpop</a></li><li><a href="#810__721">8.10 应用场景(按照销售情况排序商品)</a></li></ul><li><a href="#9_Redisbitmap_736">9 Redis位图(bitmap)</a></li><ul><li><a href="#91_setbitgetbit_752">9.1 setbit、getbit</a></li><li><a href="#92_strlen__769">9.2 strlen 统计字节数占用多少</a></li><li><a href="#93_bitcount_1_777">9.3 bitcount 全部键里含有1的个数</a></li><li><a href="#94_bitstop_783">9.4 bitstop(统计登录次数)</a></li><li><a href="#95__815">9.5 应用场景(打卡、签到、广告点击...)</a></li></ul><li><a href="#10_Redis_HyperLogLog__824">10 Redis HyperLogLog 去重复统计功能的基数估计算法</a></li><ul><li><a href="#101_pfaddpfcountpfmerge__838">10.1 pfadd、pfcount、pfmerge 添加/统计/合并</a></li><li><a href="#102_UV_856">10.2 应用场景(UV统计)</a></li></ul><li><a href="#11_RedisGEO_871">11 Redis地理空间(GEO)</a></li><ul><li><a href="#111_geoadd__892">11.1 geoadd 添加经纬度坐标</a></li><li><a href="#112_geopos__906">11.2 geopos 返回经纬度</a></li><li><a href="#113_geohash_hash_918">11.3 geohash 返回坐标hash表示</a></li><li><a href="#114_geodist__933">11.4 geodist 获取两个位置之间距离</a></li><li><a href="#115_georadius____945">11.5 georadius 以某个半径 查找附近 ***</a></li></ul><li><a href="#12_Redis_Stream_959">12 Redis 流(Stream)</a></li><ul><li><a href="#121__961">12.1 介绍</a></li><ul><li><a href="#1211_Stream_963">12.1.1 Stream流是什么</a></li><li><a href="#1211_Stream_974">12.1.1 Stream流能干什么</a></li></ul></ul><li><a href="#13_Redis_bitfield_984">13 Redis 位域(bitfield)</a></li></ul></ul></p>
<h2><a id="1_Redis__6"></a>1 Redis 十大数据类型</h2>
<p>Redis中数据是 key-value 形式存储。一般key被设定为字符串。key为字符串类型,<br />
value有如下类型:</p>
<ol>
<li>redis字符串(String)</li>
<li>redis列表(List)</li>
<li>redis哈希表(Hash)</li>
<li>redis集合(Set)</li>
<li>redis有序集合(ZSet)</li>
<li>redis地理空间(GEO)</li>
<li>reids基数统计(HyperLogLog)</li>
<li>reids位图(bitmap)</li>
<li>redis位域(bitfield)</li>
<li>redis流(Stream)</li>
</ol>
<h2><a id="2__22"></a>2 库操作</h2>
<p>1、切换数据库</p>
<pre><div class="hljs"><code class="lang-shell">select 库
</code></div></pre>
<p>2、查看当前数据库的key数量</p>
<pre><div class="hljs"><code class="lang-shell">dbsize
</code></div></pre>
<p>3、清空当前库</p>
<pre><div class="hljs"><code class="lang-shell">flushdb
</code></div></pre>
<p>4、通杀全部库</p>
<pre><div class="hljs"><code class="lang-shell">flushall
</code></div></pre>
<p>帮助:<code>hele @数据类型</code></p>
<h2><a id="3_RedisKey_54"></a>3 Redis的Key</h2>
<ul>
<li>一般成功返回1,失败返回0</li>
<li>命令不区分大小写,而key区分大小写</li>
</ul>
<h3><a id="31_keys__59"></a>3.1 keys *</h3>
<p>查看所有key</p>
<pre><div class="hljs"><code class="lang-shell">keys *
</code></div></pre>
<p>h?llo 匹配 hello, hallo 和 hxllo<br />
h*llo 匹配 hllo 和 heeeello<br />
h[ae]llo 匹配 hello and hallo, 不匹配 hillo<br />
h[^e]llo 匹配 hallo, hbllo, … 不匹配 hello<br />
h[a-b]llo 匹配 hallo 和 hbllo</p>
<h3><a id="32_dbsize_73"></a>3.2 dbsize</h3>
<p>查看当前数据库key的数量</p>
<h3><a id="32_exist_key_key_77"></a>3.2 exist key 判断key是否存在</h3>
<p>语法:<code>exist <key></code></p>
<pre><div class="hljs"><code class="lang-shell">set name 有勇气的牛排
exists name
exists name1
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/1f5e3eddde68de4011159956ff8541c7.png" alt="image.png" /></p>
<h3><a id="33_type_key_key_89"></a>3.3 type key 查看key类型</h3>
<p>语法:<code>type <key></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/cfd34f915913dac799ef38ed514b072f.png" alt="image.png" /></p>
<h3><a id="34_expire_key_key_97"></a>3.4 expire key 为key设置过期时间</h3>
<p>单位秒</p>
<p>语法:<code>expire <key> <秒数></code></p>
<pre><div class="hljs"><code class="lang-shell">set name 有勇气的牛排
expire name 5
</code></div></pre>
<h3><a id="35_ttl_key_key_110"></a>3.5 ttl key 查看key过过期时间</h3>
<p>语法:<code>ttl <key></code></p>
<p>-1:代表永不过期。<br />
-2:代表已过期</p>
<p><img src="https://www.couragesteak.com/tcos/article/193bd84f26a40311b5d076c825b5e33c.png" alt="image.png" /></p>
<h3><a id="36_move_key_key_121"></a>3.6 move key 移动key到其他库</h3>
<p>语法:<code>move key [0~15]</code></p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">移动k1到db2</span>
move k1 2
</code></div></pre>
<h3><a id="37_del_key_key_132"></a>3.7 del key 删除指定key数据</h3>
<p>1、语法:<code>del <key></code>(多个key,用空格隔开)</p>
<p>返回值:被删除key的数量。</p>
<p><img src="https://www.couragesteak.com/tcos/article/be24e47af5b3388b3575a394825c163b.png" alt="image.png" /></p>
<h3><a id="38_unlink_key_key_142"></a>3.8 unlink key 异步删除key</h3>
<p>2、语法:<code>unlink <key></code>(多个key,用空格隔开)</p>
<p>不同于del的是,unlink仅将keysoace从元数据中删除,真正的删除在后续的异步操作完成。</p>
<pre><div class="hljs"><code class="lang-shell">set name 有勇气的牛排
unlink name
</code></div></pre>
<h2><a id="4_RedisString_161"></a>4 Redis字符串(String)</h2>
<p>String是Redis最基本的数据类型,最大到512M,是二进制安全的。意味着Redis的String可以包含任何数据。比如jpg图片或者序列化的对象。</p>
<p>String的数据结构为简单东岱字符串(Simple Dynamic String,缩写SDS),是可以修改的字符串,内部结构实现上类似于JAVA的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。</p>
<p>一般内部会给字符串分配大于字符串的长度,当字符串长度小于1M时,扩容加倍增长;当大于1M时,则只会多扩1M空间,最大512M。</p>
<h3><a id="41_set__169"></a>4.1 set 命令</h3>
<p><strong>1、set</strong><br />
语法:<code>set <key> <value> <EX> <PX></code></p>
<p>属性:重复set,则覆盖原有value</p>
<p>key:键<br />
value:值<br />
ex:超时秒数<br />
PX:超时毫秒数</p>
<p>例如:key=name、value=cs,并且5秒过期</p>
<pre><div class="hljs"><code class="lang-shell">set name cs 5
</code></div></pre>
<h3><a id="42_get__189"></a>4.2 get 命令</h3>
<p>定义:获取key的value值<br />
语法:<code>get <key></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/d6693b3f00790186e939052f801b8eed.png" alt="image.png" /></p>
<h3><a id="43_append__198"></a>4.3 append 字符串内容追加</h3>
<p>定义:获取字符串内容,并且内容追加</p>
<p>语法:<code>append <key> <value></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/7d83e81f9ce3181ebd5ebf3b89db2ae4.png" alt="image.png" /></p>
<h3><a id="44_strlen__209"></a>4.4 strlen 获得值的长度</h3>
<p>语法:<code>stelen <key></code></p>
<pre><div class="hljs"><code class="lang-shell">strlen name
</code></div></pre>
<h3><a id="45_getrangesetrange__217"></a>4.5 getrange与setrange 区间范围值</h3>
<p>语法:<br />
<code>getrange <key> <起始位置> <结束位置></code><br />
<code>setrange <key> <起始位置></code>(会按位数覆盖)</p>
<p><img src="https://www.couragesteak.com/tcos/article/fad0aeb04a4b28a8505f9b1504d48174.png" alt="image.png" /></p>
<h3><a id="46__227"></a>4.6 数值自增&自减</h3>
<h4><a id="461_incrdecr_229"></a>4.6.1 incr、decr</h4>
<p>定义:将key中的的数值+1或-1,必须为数值类型,若为空,则默认为1。<br />
场景:可以做流量控制、网页访问次数统计等,具有原子性。<br />
语法:<code>incr <key></code>、<code>decr <key></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/6c81f31a02bcbaa045bbccbbe18136dc.png" alt="image.png" /></p>
<h4><a id="462_incrbydecrby_237"></a>4.6.2 incrby与decrby指定步长</h4>
<p>语法:<code>incrby <key> <步长></code>、<code>decrby <key> <步长></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/5fd05c981134a009aa3e0ad23937a36f.png" alt="image.png" /></p>
<h3><a id="47_msetmsetnxmget_kv_243"></a>4.7 mset、msetnx与mget 读/写多个k-v</h3>
<p>语法:<br />
<code>mset <key1> <value1> <key2> <value2></code><br />
<code>msetnx <key1> <value1> <key2> <value2></code><br />
<code>mget <key1> <key2></code></p>
<p>注:msetnx当且仅当所有key不存在才能成功,只要一个失败,则都失败(原子性)。</p>
<p><img src="https://www.couragesteak.com/tcos/article/9cc55e17550d47d4983b9ce70a9140b6.png" alt="image.png" /></p>
<h3><a id="48_getset__258"></a>4.8 getset 新旧址替换</h3>
<p>定义:获取旧值,并且替换为新值。</p>
<p>语法:<code>getset <key> <value></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/4d54362bd48d387c39faee5e7cd05efd.png" alt="image.png" /></p>
<h3><a id="49__268"></a>4.9 分布式锁</h3>
<h4><a id="491_setnx_270"></a>4.9.1 setnx</h4>
<p>定义:key不存在时才能成功设置值</p>
<p>语法:<code>stelen <key></code></p>
<h4><a id="492_setex_276"></a>4.9.2 setex</h4>
<p>定义:写键值对,附加过期时间</p>
<p>语法:<code>setex <key> <过期时间> <value></code></p>
<h2><a id="5_RedisList_284"></a>5 Redis列表List</h2>
<p>Redis列表是简单的字符串列表,即一键多值,按照插入顺序排序,可以插到列表头部或者尾部。</p>
<p>其底层实际是由双向列表实现,对两端的操作性能很高,通过索引下标操作中间节点的性能较差。</p>
<p><strong>数据结构</strong></p>
<p>List</p>
<h3><a id="51_lpushrpush_294"></a>5.1 lpush与rpush</h3>
<p>定义:从左边/右边插入1个或多个值。</p>
<p><code>lpush <key> <v1> <v2> ... <vn></code><br />
<code>rpush <key> <v1> <v2> ... <vn></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/6e144804d71c0c4ba7d117e9e705b723.png" alt="image.png" /></p>
<h3><a id="52_lpoprpop_304"></a>5.2 lpop与rpop</h3>
<p>定义:从左边/右边 吐出一个值。(取出来就没有了哦)</p>
<p>语法:</p>
<p><code>lpop <key> <count></code><br />
<code>rpop <key> <count></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/0e8b06c3eaf34dbd4430ae98b4326c0c.png" alt="image.png" /></p>
<h3><a id="54_rpoplpush__315"></a>5.4 rpoplpush 右出左进</h3>
<p>定义:右边pop一个值,push到左边。</p>
<p>语法:<code>rpoplpush</code> <key1> <key2></p>
<h3><a id="54_lrange_322"></a>5.4 lrange查询</h3>
<p>定义:安装索引下表查询元素(从左到右)</p>
<p><code>lrange <key> <start> <stop></code></p>
<p>查询所有:</p>
<pre><div class="hljs"><code class="lang-shell">lrange <key> 0 -1
</code></div></pre>
<h3><a id="55__334"></a>5.5 其他</h3>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">1 按照索引下标获得元素(从做到右)</span>
语法:lindex <key> <index>
<span class="hljs-meta">
# </span><span class="language-bash">2 获取列表长度</span>
语法:llen <key>
<span class="hljs-meta">
# </span><span class="language-bash">3 删除左边n个value</span>
语法:lrem <key> <n> <value>
<span class="hljs-meta">
# </span><span class="language-bash">4 插入新值</span>
linsert <key> index before/after
<span class="hljs-meta">
# </span><span class="language-bash">5 lset</span>
</code></div></pre>
<h3><a id="56__352"></a>5.6 应用场景(公众号消息订阅)</h3>
<p>微信公众号订阅消息</p>
<p>原理:创作者发布文章后,就会将文章id写入到订阅者的List中。</p>
<h2><a id="6_Redis_Hash_362"></a>6 Redis 哈希(Hash)</h2>
<ul>
<li>Redis hash是一个键值对集合。</li>
<li>Redis hash是一个string类型的files和value的映射表,hash特别适合用于存储对象。</li>
<li>kv模式不变,但v是一个键值对。</li>
</ul>
<p><strong>数据结构</strong></p>
<p>Hash类型对应的数据结构有两种:</p>
<ol>
<li>ziplist(压缩列表)</li>
<li>hashtable(哈希表)</li>
</ol>
<p>当field-value 长度较短且个数较少时,使用ziplist,否则使用hashtable。</p>
<h3><a id="61_hsethget_378"></a>6.1 hset、hget</h3>
<p>给集合key的filed复制value<br />
<code>hset <key> <filed> <value></code></p>
<p><code>hget <key> <filed></code></p>
<pre><div class="hljs"><code class="lang-shell">hset user:cs age 20
hget user:cs age
</code></div></pre>
<h3><a id="62_hmsethmget_390"></a>6.2 hmset、hmget批量设置值</h3>
<p><code>hmset <key1> <filed1> <value1> <filed2> <value2> ...</code></p>
<pre><div class="hljs"><code class="lang-shell">hmset user name cs age 20 id 001
hmget user name age id
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/6c650008ceccf066ca79589fdc6df41d.png" alt="image.png" /></p>
<h3><a id="63_hgetallhlenhdel_402"></a>6.3 hgetall、hlen、hdel</h3>
<p><code>hgetall <key></code>:获取所有子键</p>
<p><code>hlen <key></code>:获取键长度</p>
<p><code>hdel <key></code>:删除键</p>
<p><img src="https://www.couragesteak.com/tcos/article/d79e8a5576a6d48a7f322cb964e26894.png" alt="image.png" /></p>
<h3><a id="64_hexistshkeyshvals_412"></a>6.4 hexists、hkeys、hvals</h3>
<p><code>hexists <key1> <filed></code>: 查看哈希集合key中filed是否存在</p>
<p><code>hkeys <key></code>: 列出哈希集合key中所有field</p>
<p><code>hvals <key></code>: 列出哈希集合key的所有value</p>
<h3><a id="65_hincrby__420"></a>6.5 hincrby 数值增减</h3>
<p>为哈希集合key的field的值加减指定值</p>
<p><code>hincrby <key> <filed> <increment></code>:</p>
<h3><a id="66_hsetnx__428"></a>6.6 hsetnx 不存在新增(分布式)</h3>
<p>新增哈希集合key的filed域,当且仅当filed不存在</p>
<p><code>hsetnx <key> <field> <value></code></p>
<p><img src="https://www.couragesteak.com/tcos/article/93cefac8511ce7894cd7f2b5de9efc92.png" alt="image.png" /></p>
<h3><a id="67__436"></a>6.7 应用场景(购物车)</h3>
<p>小公司可以用</p>
<p>例如:购物车中商品的数量</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">场景</span>
bigkey smallkey value
用户id 商品id 商品属性(数量)
<span class="hljs-meta">
# </span><span class="language-bash">新增商品(001用户,加购2号商品,5个)</span>
hset shopcar:user001 2 5
<span class="hljs-meta"># </span><span class="language-bash">增加商品数量</span>
hincrby shopcar:user001 2 1
<span class="hljs-meta"># </span><span class="language-bash">加购商品总数量</span>
hlen shopcar:user001
<span class="hljs-meta"># </span><span class="language-bash">全部选择</span>
hget shopcar:user001
</code></div></pre>
<h2><a id="7_RedisSet_458"></a>7 Redis集合(Set)</h2>
<ul>
<li>单key,多value,且不重复</li>
</ul>
<p>Redis Set对外提供的功能与list类似,都提供的是列表功能,其特殊之处在于set可以自动排重,而且set提供了判断成员是否存在的接口,list是没有的。</p>
<p>Redis的set集合是string类型的无序集合,底层为一个value为null的hash表,故新增、删除、查询的复杂度都是 O(1),即查询时间不随数据量增减而改变。</p>
<p><strong>数据结构</strong></p>
<p>其数据结构由dict字典实现(字典由哈希表实现)</p>
<p>Java中的HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。</p>
<p>Redis的set结构也一样,其内部使用hash结构,所有value指向同一个值。</p>
<h3><a id="71_saddsmembers_476"></a>7.1 sadd、smembers</h3>
<p>1、将一个或多个member元素加入到集合key中,已经存在的member会被忽略。<br />
<code>sadd <key> <value1> <value2> ...</code></p>
<p>2、获取集合key的所有值</p>
<p><code>smembers <key></code></p>
<h3><a id="72_sismember__487"></a>7.2 sismember 判断值是否存在集合中</h3>
<p>判断集合key,是否包含value值。</p>
<p><code>sismember <key> <value></code></p>
<h3><a id="73_scard__495"></a>7.3 scard 获取集合元素个数</h3>
<p>返回集合key的元素个数</p>
<p><code>scard <key></code></p>
<h3><a id="74_srem__503"></a>7.4 srem 删除集合中指定元素</h3>
<p>删除集合中的某个元素</p>
<p><code>srem <key> <value1> <value2> ...</code></p>
<h3><a id="76_spop_pop_511"></a>7.6 spop 随机从集合pop值,且删除</h3>
<p>随机从集合中吐出n个值(n可以不写,默认为1)</p>
<p><code>spop <key> <n></code></p>
<h3><a id="77_srandmember__519"></a>7.7 srandmember 随机取值,不删除</h3>
<p>随机从集合中取出n个值,但不从集合中删除</p>
<p><code>srandmember <key> <n></code></p>
<h3><a id="78_smove__527"></a>7.8 smove 移动</h3>
<p>将value从一个集合key1移动到集合key2中。</p>
<p><code>smove <key1> <key2> <value></code></p>
<h3><a id="79_sintersunion_sdiff__535"></a>7.9 sinter、sunion 、sdiff 集合运算(交并差集)</h3>
<p>获取两个集合的<strong>交集</strong></p>
<p><code>sinter <ke1> <key2></code></p>
<p>获取两个集合的<strong>并集</strong></p>
<p><code>sunion <key1> <key2></code></p>
<p>获取两个集合的<strong>差集</strong></p>
<p><code>sdiff <key1> <key2></code></p>
<h3><a id="710__551"></a>7.10 应用场景(抽奖、共同好友、可能认识的人…)</h3>
<p>抽奖</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">参与抽奖</span>
sadd key 用户ID
<span class="hljs-meta"># </span><span class="language-bash">显示多少人参数抽奖</span>
scard key
<span class="hljs-meta"># </span><span class="language-bash">随机选取n个中奖人</span>
srandmember key 2 # 元素不删除
spop key 2 # 元素会删除(即不允许重复抽奖)
</code></div></pre>
<p>例如:朋友圈同赞朋友</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">新增点赞</span>
sadd pub:msgID 点赞用户ID1 点赞用户ID2
<span class="hljs-meta"># </span><span class="language-bash">取消点赞</span>
srem pub:msgID 点赞用户ID
<span class="hljs-meta"># </span><span class="language-bash">展现所有点赞用户</span>
smembers pub:msgID
<span class="hljs-meta"># </span><span class="language-bash">点赞用户数统计</span>
scard pub:msgID
</code></div></pre>
<p>可能认识的人、猜你喜欢</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">原理:取差集</span>
sdiff user1 user2
</code></div></pre>
<h2><a id="8_Redis_Zsetsorted_set_592"></a>8 Redis有序结合 Zset(sorted set)</h2>
<p>zset与set非常相似,是一个没有<strong>重复元素</strong>的字符串集合。</p>
<p>不通之处是有序集合的每个成员关联了一个<strong>评分(score)</strong>,这个评分被用来按照从最低到最高分的方式排序集合中的成员。(评分可以被重复)</p>
<p><strong>数据结构</strong></p>
<p>SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map(String, Double), 可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部元素会按照权重score进行排序,可以得到每个元素的名词,还可以通过score范围来获取元素列表。</p>
<p>zset底层使用了两个数据结构:</p>
<ol>
<li>hash,hash的作用是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到响应的score值。</li>
<li>跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。</li>
</ol>
<h3><a id="81_zadd___609"></a>8.1 zadd 插入 元素+分数</h3>
<p>1、将一个或多个member元素及score值加入到有序集key中</p>
<p><code>zadd <key> <score1> <value> <score2> <value2></code></p>
<pre><div class="hljs"><code class="lang-shell">zadd cs 99 math 98 chinese 100 computer
</code></div></pre>
<h3><a id="82_zrangezrevrange_623"></a>8.2 zrange、zrevrange</h3>
<ul>
<li>zrange:安顺序取</li>
<li>zrevrange:顺序反转</li>
</ul>
<p>获取有序集合key中,下表在<start>-<stop>之间的元素</p>
<p>[WITHSOCRES]参数代表,分数也被返回。</p>
<p><code>zrange <key> <start> <stop> [WITHSOCRES]</code></p>
<p>取所有:</p>
<pre><code class="lang-shelll"> zrange cs 0 -1
</code></pre>
<p><img src="https://www.couragesteak.com/tcos/article/ca369b1dba7cf111b559b5d22782a628.png" alt="image.png" /></p>
<p>带分数</p>
<pre><div class="hljs"><code class="lang-shell">zrange cs 0 -1 withscores
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/fc1a1a8be221f312719e38631e3f3c62.png" alt="image.png" /></p>
<h3><a id="83_zrangebyscore_652"></a>8.3 zrangebyscore</h3>
<p>按score范围查(例如200->300之间),从小到大</p>
<p><code>zrangebyscore <key> 200 300 withscores</code></p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">拿出99~100的科目 包含99</span>
zrangebyscore cs 99 100 withscores
<span class="hljs-meta"># </span><span class="language-bash">拿出99~100的科目 不包含99</span>
zrangebyscore cs (99 100 withscores
<span class="hljs-meta">
# </span><span class="language-bash">拿出90~100的科目 前两个</span>
zrangebyscore cs 90 100 withscores limit 0 2
</code></div></pre>
<h3><a id="84_zscore__670"></a>8.4 zscore 获取元素的分数</h3>
<p><code>zscore key member</code></p>
<pre><div class="hljs"><code class="lang-shell">zscore cs computer
</code></div></pre>
<h3><a id="85_zrem_680"></a>8.5 zrem删除</h3>
<p>删除指定元素</p>
<p><code>zrem <key> <value></code></p>
<h3><a id="86_zincrby_688"></a>8.6 zincrby增加</h3>
<p><code>zincrby <key> <increment> <value></code></p>
<h3><a id="87_zcount__694"></a>8.7 zcount 获得分数区间的元素个数</h3>
<p>获得分数区间的元素个数</p>
<p><code>zcount <key> <min> <max></code></p>
<h3><a id="88_zrank__702"></a>8.8 zrank 获取下标</h3>
<ul>
<li>zrevrank</li>
</ul>
<p>返回集合中的下标,从0开始</p>
<p><code>zrank <key> <value></code></p>
<h3><a id="89_zmpop_712"></a>8.9 zmpop</h3>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">弹出最小的</span>
zmpop 1 cs min count 1
</code></div></pre>
<h3><a id="810__721"></a>8.10 应用场景(按照销售情况排序商品)</h3>
<p>定义商品销售排行榜(sorted set集合),key为good:sellsort,分数为商品销售数量</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">商品1001销量为9,商品1002销量为15</span>
zadd goods: sellsort 9 1001 15 1002
<span class="hljs-meta"># </span><span class="language-bash">有一个客户又买了2件1001</span>
zincrby goods: sellsort 2 1001
<span class="hljs-meta"># </span><span class="language-bash">求商品销量前10名(定时刷新获取)</span>
zrange goods:sellsort 0 9 withscores
</code></div></pre>
<h2><a id="9_Redisbitmap_736"></a>9 Redis位图(bitmap)</h2>
<p>**定义:**由0和1状态表现的二进制位的bit数组</p>
<p><strong>说明:</strong></p>
<p><strong>用String类型作为底层数据结构实现的一种统计二值状态的数据类型。</strong></p>
<p>位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成。每个二进制位都对应一个偏移量(我们称之为索引)。</p>
<p>Bitmap支持最大的位数为2<sup>32位,它可以极大的节约存储空间,使用512M内存就可以存储多达42.9亿的字节信息(2</sup>32=4294967296)</p>
<h3><a id="91_setbitgetbit_752"></a>9.1 setbit、getbit</h3>
<p>语法: <code>setbit <key> offset value</code></p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">第1、7天有签到</span>
setbit k1 1 1
setbit k1 7 1
<span class="hljs-meta">
# </span><span class="language-bash">获取第6天签到情况</span>
getbit k1 6 # 结果0
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/687f730e02becf085326f5d77c68cdf1.png" alt="image.png" /></p>
<h3><a id="92_strlen__769"></a>9.2 strlen 统计字节数占用多少</h3>
<p>原理:这里8位为一组,不是字符串长度多少而占用几个字节,而是超过8位一组,byte再扩容。</p>
<p>语法:<code>strlen <key></code>,(输出字节数)</p>
<h3><a id="93_bitcount_1_777"></a>9.3 bitcount 全部键里含有1的个数</h3>
<p>语法:<code>bitcount <key></code></p>
<h3><a id="94_bitstop_783"></a>9.4 bitstop(统计登录次数)</h3>
<p>查看那连续2天签到用户</p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">映射用户</span>
hset uid:map 0 uid_1
hset uid:map 1 uid_2
<span class="hljs-meta">
# </span><span class="language-bash">查看所有用户</span>
hgetall uid:map
<span class="hljs-meta">
# </span><span class="language-bash">记录登录过得用户:</span>
<span class="hljs-meta"># </span><span class="language-bash">10号,0~3号用户登录过</span>
setbit 20230310 0 1
setbit 20230310 1 1
setbit 20230310 2 1
setbit 20230310 3 1
<span class="hljs-meta"># </span><span class="language-bash">11号,0、2号用户登录过</span>
setbit 20230310 0 1
setbit 20230311 2 1
<span class="hljs-meta">
# </span><span class="language-bash">查看那20230311,0号用户有没有登录过</span>
getbit 20230311 0
<span class="hljs-meta">
# </span><span class="language-bash">统计指定10、11号都登录的用户</span>
bitop and haslogin 20230310 20230311
bitcount haslogin
</code></div></pre>
<h3><a id="95__815"></a>9.5 应用场景(打卡、签到、广告点击…)</h3>
<ul>
<li>用户状态统计</li>
<li>用户是否登录过Y、N;比如每日签到送积分</li>
<li>电影、广告是否被点击播放过</li>
<li>打卡上下班,签到统计</li>
</ul>
<h2><a id="10_Redis_HyperLogLog__824"></a>10 Redis HyperLogLog 去重复统计功能的基数估计算法</h2>
<p>定义:去重复统计功能的基数估计算法</p>
<p>基数:是一种数据集,去重复后的真实个数</p>
<p>缺点:有个标准误差在0.81%</p>
<p>在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算将近2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。</p>
<p>但是,因为HyperLogLog只会根据输入元素来计算基数,而不会存储元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。</p>
<h3><a id="101_pfaddpfcountpfmerge__838"></a>10.1 pfadd、pfcount、pfmerge 添加/统计/合并</h3>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">模拟第1、2天的ip</span>
pfadd ip01 1 1 2 2 3 4 5 6
pfadd ip02 8 8 9 9
<span class="hljs-meta">
# </span><span class="language-bash">统计ip数量</span>
pfcount ip01 # 6个
pfcount ip02 # 2个
<span class="hljs-meta">
# </span><span class="language-bash">合并1、2两天的ip</span>
pfmerge disresult ip01 ip02
pfcount disresult # 8个
</code></div></pre>
<h3><a id="102_UV_856"></a>10.2 应用场景(UV统计)</h3>
<ul>
<li>统计某个网站的UV、统计文章的UV</li>
<li>用户搜索网站关键词的数量</li>
<li>统计用户每天搜索不同词条个数</li>
</ul>
<p>什么是UV:</p>
<ul>
<li>Unique Vistor:独立访客,一般理解为客户端IP</li>
<li>需要去重处理的情况,一个IP为一次</li>
</ul>
<h2><a id="11_RedisGEO_871"></a>11 Redis地理空间(GEO)</h2>
<ul>
<li>Redis在3.2版本以后增加了地理位置的处理</li>
<li>类型为zset</li>
</ul>
<p>由于中文乱码,连接需要加参数</p>
<pre><div class="hljs"><code class="lang-shell">redis-cli -a 123456 --raw
</code></div></pre>
<p>百度接口(获取经纬度):https://api.map.baidu.com/lbsapi/getpoint/</p>
<p>天安门:<code>116.404082,39.909187</code></p>
<p>泰山:<code>117.094738,36.269893</code></p>
<h3><a id="111_geoadd__892"></a>11.1 geoadd 添加经纬度坐标</h3>
<p>语法:<code>geoadd key 经度 纬度 member</code></p>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">添加</span>
geoadd city 116.404082 39.909187 "天安门" 117.094738 36.269893 "泰山"
<span class="hljs-meta">
# </span><span class="language-bash">查看</span>
zrange city 0 -1
</code></div></pre>
<h3><a id="112_geopos__906"></a>11.2 geopos 返回经纬度</h3>
<p>语法:<code>geopos <key> <member> [member ...]</code></p>
<pre><div class="hljs"><code class="lang-shell">geopos city 天安门 泰山
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/6b3571a757a7303f34e4521f60f6c916.png" alt="image.png" /></p>
<h3><a id="113_geohash_hash_918"></a>11.3 geohash 返回坐标hash表示</h3>
<ul>
<li>geohash算法生成base32编码值</li>
<li>3维变2维变1维</li>
</ul>
<p>语法:<code>geohash <key > <member> [member ...]</code></p>
<pre><div class="hljs"><code class="lang-shell">geohash city 天安门 泰山
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/07f712d35834315ad0f145d37c4e4990.png" alt="image.png" /></p>
<h3><a id="114_geodist__933"></a>11.4 geodist 获取两个位置之间距离</h3>
<p>语法:<code>geodist <key > <member1> <member2></code></p>
<p>单位:m、km、ft、mi</p>
<pre><div class="hljs"><code class="lang-shell">geodist city 天安门 泰山 km
</code></div></pre>
<h3><a id="115_georadius____945"></a>11.5 georadius 以某个半径 查找附近 ***</h3>
<p>定义:以给定的经纬度为中心,返回键包含的位置元素中,与中心的距离不超过给定最大距离的所有位置元素。</p>
<p>语法:``</p>
<pre><div class="hljs"><code class="lang-shell">georadius city 116.404082 39.909187 500 km withdist withcoord count 10 withhash desc
georadiusbymember city 天安门 500 km withdist withcoord count 10 withhash desc
</code></div></pre>
<h2><a id="12_Redis_Stream_959"></a>12 Redis 流(Stream)</h2>
<h3><a id="121__961"></a>12.1 介绍</h3>
<h4><a id="1211_Stream_963"></a>12.1.1 Stream流是什么</h4>
<p>在Redis 5.0之前通过Redis实现消息队列,有两种方案:</p>
<ul>
<li>list实现消息队列(点对点模式)(简单实现)</li>
<li>Pub/Sub</li>
</ul>
<p>但是 发布订阅Pub/Sub模式有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息机会被丢弃,而且也没有ACK机制来保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。</p>
<p>因此新增了Steam实现了Redis版的消息中间件。</p>
<h4><a id="1211_Stream_974"></a>12.1.1 Stream流能干什么</h4>
<p>实现消息队列、支持消息的持久化、支持自动生成全局唯一ID、支持ack确认消息的模式、支持消费组模式登,让消息队列更加的稳定和可靠。</p>
<p>这里建议使用专用的MQ,大厂不会采用。</p>
<h2><a id="13_Redis_bitfield_984"></a>13 Redis 位域(bitfield)</h2>
<ul>
<li>了解即可(大厂也基本不用)</li>
</ul>
<p>bitfield命令可以将一个Redis字符串看做是一个由二进制位组成的数组,并对这个数组中任意偏移进行访问。</p>
<p>参考地址:</p>
<p>https://www.bilibili.com/video/BV1YK411M7MG</p>
<p>https://www.bilibili.com/video/BV1Rv41177Af</p>
<p>https://www.bilibili.com/video/BV13R4y1v7sP(尚硅谷 阳哥)</p>

评论区