1 前言
Milvus 是一个 开源的向量数据库,用于存储、索引和检索高维向量数据,特别适用于AI 应用场景,如:
- 向量检索(以图搜图、语义搜索)
- 自然语言处理(文本相似度、QA 系统)
- 图像、音频、生物特征匹配等
由 Zilliz 公司 开发,支持百万甚至十亿级向量的高性能相似度检索。
1.1 环境
pip install pymilvus==2.6.0
2 Collection 操作
2.1 创建 Collection
在定义字段的时候,需要提前规划好需要使用到的字段,Milvus不支持动态新增字段。
from pymilvus import (
connections, FieldSchema, CollectionSchema, DataType,
Collection, utility
)
connections.connect(db_name="cs_blog", host='192.168.56.20', port='19530')
collection_name = "article"
if utility.has_collection(collection_name):
print("集合已存在")
Collection(collection_name).drop()
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=255),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
]
schema = CollectionSchema(fields, description="博客文章集合")
collection = Collection(name=collection_name, schema=schema)
collection.create_index(field_name="embedding", index_params={
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128}
})
collection.load()
3 获取Client
from pymilvus import connections, Collection
connections.connect(db_name="cs_blog", host='192.168.56.20', port='19530')
collection = Collection("article")
print(collection)
4 Doc 操作
4.1 插入数据
import numpy as np
from 获取Client import collection
article = {
"id": 1,
"title": "Milvus向量数据库介绍",
"author": "有勇气的牛排",
"content": "Milvus 是一个开源的向量数据库,专门用于处理海量高维向量数据的相似度搜索。",
"embedding": np.random.rand(384).astype("float32").tolist()
}
data = [
[article["id"]],
[article["title"]],
[article["author"]],
[article["content"]],
[article["embedding"]]
]
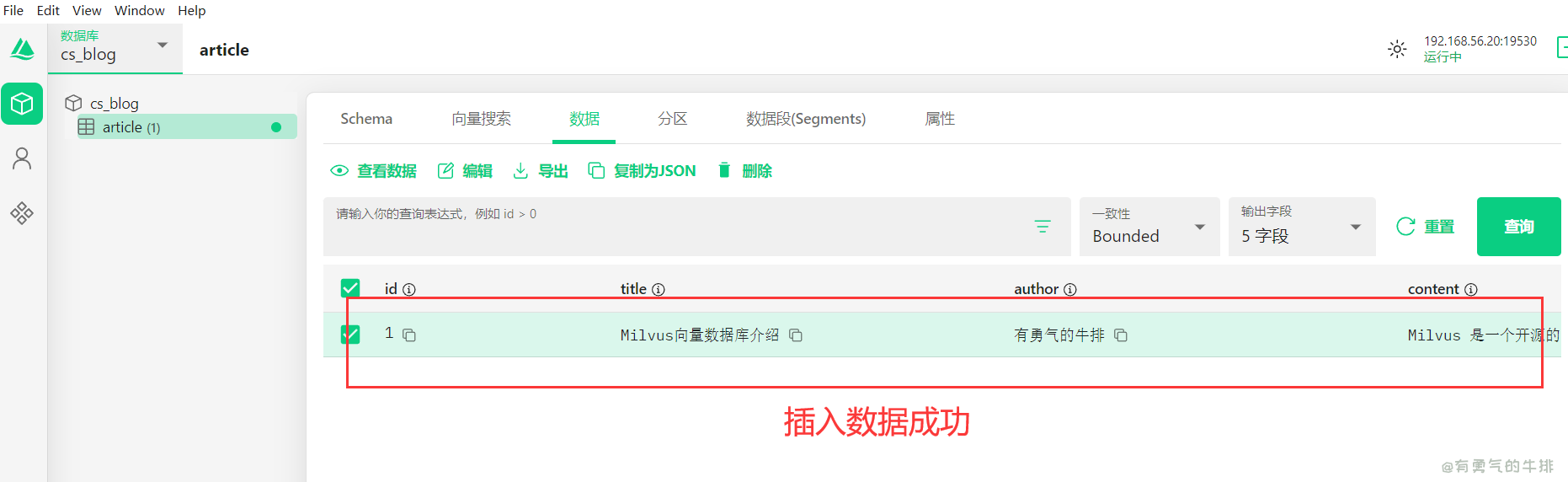
collection.insert(data)
collection.flush()
print("✅ 插入成功")
4.2 删除数据
from 获取Client import collection
article_id = 1
expr = f"id=={article_id}"
collection.delete(expr)
collection.flush()
print(f"🗑️ 已删除 ID={article_id} 的文章")
4.3 相似搜索
import numpy as np
from AI.ai_code_test.Milvus案例.获取Client import collection
query_vec = np.random.rand(384).astype("float32").tolist()
top_k = 3
collection.load()
results = collection.search(
data=[query_vec],
anns_field="embedding",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=top_k,
output_fields=["id", "title", "content"]
)
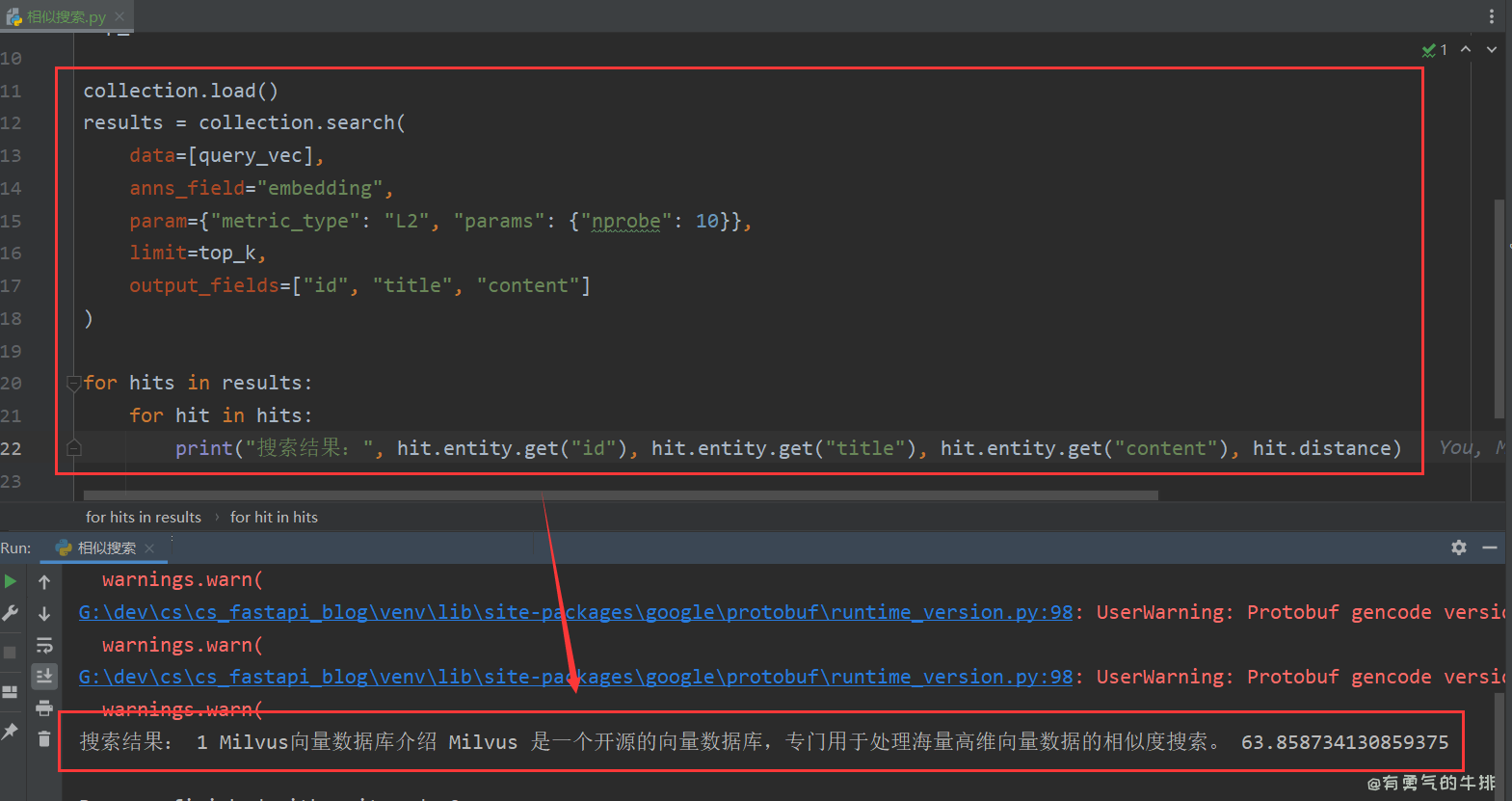
for hits in results:
for hit in hits:
print("\t", hit.entity.get("id"), hit.entity.get("title"), hit.entity.get("content"), hit.distance)
<h2><a id="1__0"></a>1 前言</h2>
<p><strong>Milvus</strong> 是一个 <strong>开源的向量数据库</strong>,用于存储、索引和检索<strong>高维向量数据</strong>,特别适用于<strong>AI 应用场景</strong>,如:</p>
<ul>
<li>向量检索(以图搜图、语义搜索)</li>
<li>自然语言处理(文本相似度、QA 系统)</li>
<li>图像、音频、生物特征匹配等</li>
</ul>
<p>由 <strong>Zilliz 公司</strong> 开发,支持百万甚至十亿级向量的高性能相似度检索。</p>
<h3><a id="11__10"></a>1.1 环境</h3>
<pre><div class="hljs"><code class="lang-shell">pip install pymilvus==2.6.0
</code></div></pre>
<h2><a id="2_Collection__16"></a>2 Collection 操作</h2>
<h3><a id="21__Collection_18"></a>2.1 创建 Collection</h3>
<p>在定义字段的时候,需要提前规划好需要使用到的字段,Milvus不支持动态新增字段。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> pymilvus <span class="hljs-keyword">import</span> (
connections, FieldSchema, CollectionSchema, DataType,
Collection, utility
)
<span class="hljs-comment"># ----------------- 连接 Milvus -----------------</span>
connections.connect(db_name=<span class="hljs-string">"cs_blog"</span>, host=<span class="hljs-string">'192.168.56.20'</span>, port=<span class="hljs-string">'19530'</span>)
<span class="hljs-comment"># ----------------- 创建集合 -----------------</span>
collection_name = <span class="hljs-string">"article"</span>
<span class="hljs-keyword">if</span> utility.has_collection(collection_name):
<span class="hljs-built_in">print</span>(<span class="hljs-string">"集合已存在"</span>)
Collection(collection_name).drop()
fields = [
FieldSchema(name=<span class="hljs-string">"id"</span>, dtype=DataType.INT64, is_primary=<span class="hljs-literal">True</span>, auto_id=<span class="hljs-literal">False</span>),
FieldSchema(name=<span class="hljs-string">"title"</span>, dtype=DataType.VARCHAR, max_length=<span class="hljs-number">255</span>),
FieldSchema(name=<span class="hljs-string">"content"</span>, dtype=DataType.VARCHAR, max_length=<span class="hljs-number">65535</span>),
FieldSchema(name=<span class="hljs-string">"embedding"</span>, dtype=DataType.FLOAT_VECTOR, dim=<span class="hljs-number">384</span>),
]
schema = CollectionSchema(fields, description=<span class="hljs-string">"博客文章集合"</span>)
collection = Collection(name=collection_name, schema=schema)
<span class="hljs-comment"># 建立索引</span>
collection.create_index(field_name=<span class="hljs-string">"embedding"</span>, index_params={
<span class="hljs-string">"index_type"</span>: <span class="hljs-string">"IVF_FLAT"</span>,
<span class="hljs-string">"metric_type"</span>: <span class="hljs-string">"L2"</span>,
<span class="hljs-string">"params"</span>: {<span class="hljs-string">"nlist"</span>: <span class="hljs-number">128</span>}
})
collection.load()
</code></div></pre>
<h2><a id="3_Client_57"></a>3 获取Client</h2>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> pymilvus <span class="hljs-keyword">import</span> connections, Collection
<span class="hljs-comment"># 连接客户端</span>
connections.connect(db_name=<span class="hljs-string">"cs_blog"</span>, host=<span class="hljs-string">'192.168.56.20'</span>, port=<span class="hljs-string">'19530'</span>)
<span class="hljs-comment"># 获取集合对象(等同于实例化一个操作集合的客户端对象)</span>
collection = Collection(<span class="hljs-string">"article"</span>)
<span class="hljs-built_in">print</span>(collection)
</code></div></pre>
<h2><a id="4_Doc__72"></a>4 Doc 操作</h2>
<h3><a id="41__74"></a>4.1 插入数据</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">import</span> numpy <span class="hljs-keyword">as</span> np
<span class="hljs-comment"># 以字典形式表示文章</span>
<span class="hljs-keyword">from</span> 获取Client <span class="hljs-keyword">import</span> collection
article = {
<span class="hljs-string">"id"</span>: <span class="hljs-number">1</span>,
<span class="hljs-string">"title"</span>: <span class="hljs-string">"Milvus向量数据库介绍"</span>,
<span class="hljs-string">"author"</span>: <span class="hljs-string">"有勇气的牛排"</span>,
<span class="hljs-string">"content"</span>: <span class="hljs-string">"Milvus 是一个开源的向量数据库,专门用于处理海量高维向量数据的相似度搜索。"</span>,
<span class="hljs-string">"embedding"</span>: np.random.rand(<span class="hljs-number">384</span>).astype(<span class="hljs-string">"float32"</span>).tolist()
}
<span class="hljs-comment"># 插入(注意:字段必须按集合 schema 顺序构造 list)</span>
data = [
[article[<span class="hljs-string">"id"</span>]],
[article[<span class="hljs-string">"title"</span>]],
[article[<span class="hljs-string">"author"</span>]],
[article[<span class="hljs-string">"content"</span>]],
[article[<span class="hljs-string">"embedding"</span>]]
]
collection.insert(data)
collection.flush()
<span class="hljs-built_in">print</span>(<span class="hljs-string">"✅ 插入成功"</span>)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/5c2fe7505074af044e086330a0c10d73.png" alt="image.png" /></p>
<h3><a id="42__106"></a>4.2 删除数据</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> 获取Client <span class="hljs-keyword">import</span> collection
article_id = <span class="hljs-number">1</span>
expr = <span class="hljs-string">f"id==<span class="hljs-subst">{article_id}</span>"</span>
collection.delete(expr)
collection.flush()
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"🗑️ 已删除 ID=<span class="hljs-subst">{article_id}</span> 的文章"</span>)
</code></div></pre>
<h3><a id="43__119"></a>4.3 相似搜索</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">import</span> numpy <span class="hljs-keyword">as</span> np
<span class="hljs-comment"># 以字典形式表示文章</span>
<span class="hljs-keyword">from</span> AI.ai_code_test.Milvus案例.获取Client <span class="hljs-keyword">import</span> collection
<span class="hljs-comment"># 文本向量</span>
query_vec = np.random.rand(<span class="hljs-number">384</span>).astype(<span class="hljs-string">"float32"</span>).tolist()
top_k = <span class="hljs-number">3</span>
collection.load()
results = collection.search(
data=[query_vec],
anns_field=<span class="hljs-string">"embedding"</span>,
param={<span class="hljs-string">"metric_type"</span>: <span class="hljs-string">"L2"</span>, <span class="hljs-string">"params"</span>: {<span class="hljs-string">"nprobe"</span>: <span class="hljs-number">10</span>}},
limit=top_k,
output_fields=[<span class="hljs-string">"id"</span>, <span class="hljs-string">"title"</span>, <span class="hljs-string">"content"</span>]
)
<span class="hljs-keyword">for</span> hits <span class="hljs-keyword">in</span> results:
<span class="hljs-keyword">for</span> hit <span class="hljs-keyword">in</span> hits:
<span class="hljs-built_in">print</span>(<span class="hljs-string">"\t"</span>, hit.entity.get(<span class="hljs-string">"id"</span>), hit.entity.get(<span class="hljs-string">"title"</span>), hit.entity.get(<span class="hljs-string">"content"</span>), hit.distance)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/3080b8512528cc38bfdf13520b90a772.png" alt="image.png" /></p>

评论区