SentenceTransformer 句子、段落、文本转换成向量 embedding
有勇气的牛排
3569
AI大模型
2025-04-19 21:03:47
1 前言
1.1 摘要
SentenceTransformer是一个基于封装的高级库,专门用来将句子、段落、文本转换成向量(Embedding),方便于:
- 文本相似度计算
- 信息检索、
- 聚类、分类
- 向量数据库(Milvus、FAISS)
- 问答系统、聊天机器人
它是Hugging Face的Transformers和PyTorch的一种高级封装。
1.2 它和普通BERT有什么区别🤔
| 特性 |
SentenceTransformer |
普通 Transformers(如 BERT) |
| 输入 |
整句或多句 |
单个句子 |
| 输出 |
一个固定维度向量 |
每个词一个向量,CLS输出不一定稳定 |
| 适用场景 |
相似度、检索、匹配等 |
分类、NER、QA等任务 |
| 使用方便度 |
✅ 高度封装 |
❌需要手动处理向量、聚合等 |
2 常用模型推荐
| 模型名称 |
向量维度 |
模型大小 |
内存占用(加载后) |
特点 |
| all-MiniLM-L6-v2 |
384 |
~80MB |
~400MB |
🚀 快速、轻量,适合中文和英文 |
| paraphrase-MiniLM-L6-v2 |
384 |
~80MB |
~400MB |
英文表现好、语义相似度强 |
| multi-qa-MiniLM-L6-cos-v1 |
384 |
~80MB |
~400MB |
多语言问答优化版本 |
| all-mpnet-base-v2 |
768 |
~420MB |
~1.3GB |
精度更高,英文效果佳 |
| paraphrase-multilingual-MiniLM-L12-v2 |
384 |
~190MB |
~800MB |
多语言支持(包括中文) |
| distiluse-base-multilingual-cased-v2 |
512 |
~230MB |
~1GB |
多语言支持、效果稳定 |
| LaBSE |
768 |
~1.3GB |
~2.5GB |
跨语言最佳选择(谷歌出品) |
阿里的开源模型推荐(中文向量)
| 模型名称 |
来源 |
向量维度 |
模型大小 |
加载内存 (CPU) |
显存占用 (GPU) |
特点 |
| GanymedeNil/text2vec-base-chinese |
阿里达摩院&社区维护 |
768 |
~400MB |
~1.2GB |
~1.4GB |
🔥 中文相似度表现优异,经典款 |
| shibing624/text2vec-base-multilingual |
阿里社区衍生 |
768 |
~400MB |
~1.2GB |
~1.4GB |
多语言兼容(中英等) |
| damotext/sbert-chinese-general-v2 |
阿里达摩院 |
768 |
~420MB |
~1.2GB |
~1.4GB |
精度高,适合通用相似度 |
| Alibaba-NLP/gte-base-zh |
阿里 |
768 |
~420MB |
~1.2GB |
~1.4GB |
适合中文搜索、问答等场景 |
| damotext/bge-large-zh-v1.5 |
阿里达摩院 BGE 系列 |
1024 |
~1.2GB |
~3.5GB |
~4.5GB |
🔥 精度最强,适合召回、RAG |
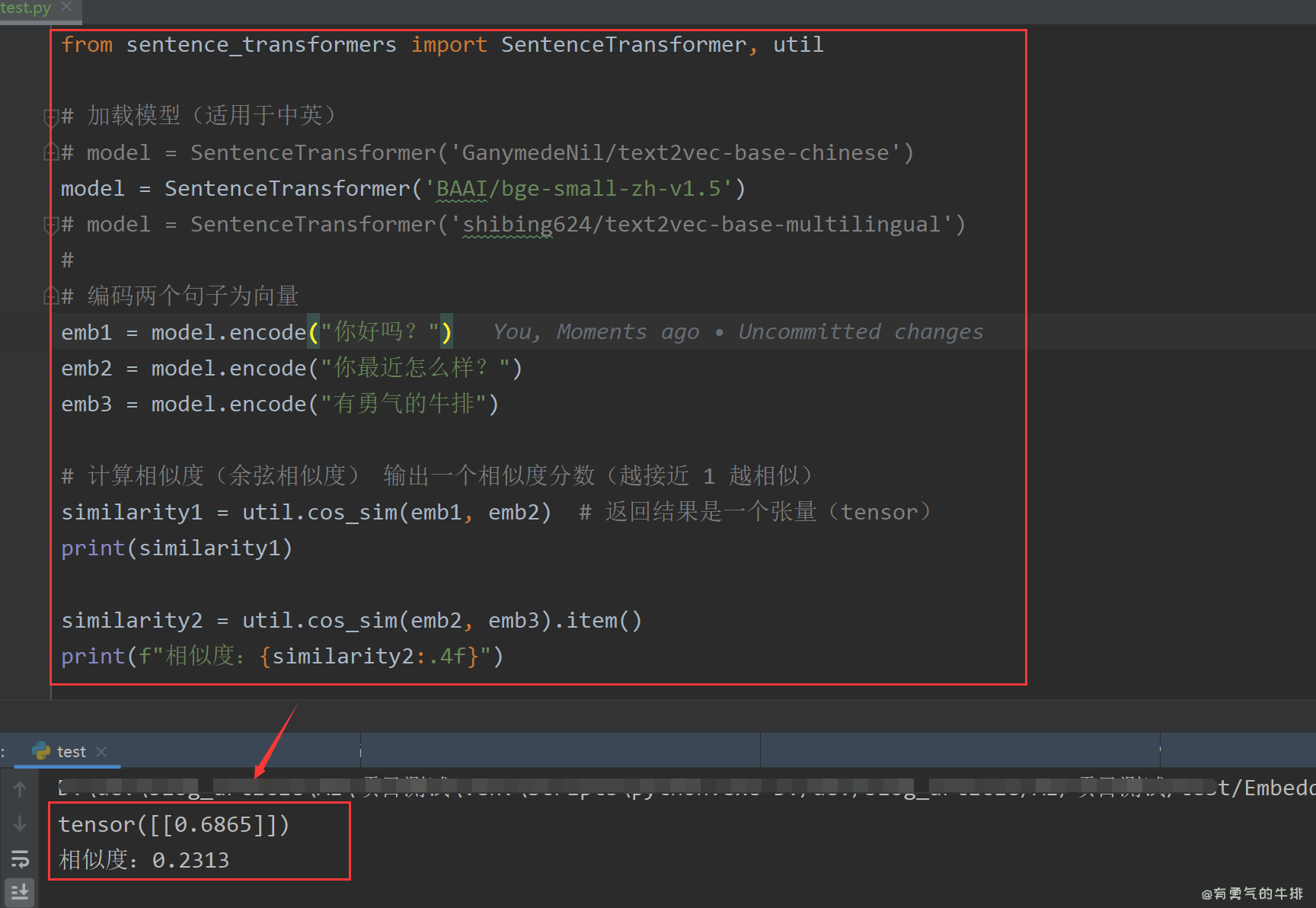
3 文本向量化案例
sentence-transformers==4.1.0
huggingface_hub[hf_xet]
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
emb1 = model.encode("你好吗?")
emb2 = model.encode("你最近怎么样?")
similarity = util.cos_sim(emb1, emb2)
print(similarity)
模型1测试

模型2测试
<h2><a id="1__0"></a>1 前言</h2>
<h3><a id="11__2"></a>1.1 摘要</h3>
<p><strong>SentenceTransformer</strong>是一个基于封装的高级库,专门用来将<strong>句子、段落、文本转换成向量</strong>(Embedding),方便于:</p>
<ul>
<li>文本相似度计算</li>
<li>信息检索、</li>
<li>聚类、分类</li>
<li>向量数据库(Milvus、FAISS)</li>
<li>问答系统、聊天机器人</li>
</ul>
<p>它是Hugging Face的Transformers和PyTorch的一种高级封装。</p>
<h3><a id="12_BERT_14"></a>1.2 它和普通BERT有什么区别🤔</h3>
<table>
<thead>
<tr>
<th>特性</th>
<th>SentenceTransformer</th>
<th>普通 Transformers(如 BERT)</th>
</tr>
</thead>
<tbody>
<tr>
<td>输入</td>
<td>整句或多句</td>
<td>单个句子</td>
</tr>
<tr>
<td>输出</td>
<td>一个固定维度向量</td>
<td>每个词一个向量,CLS输出不一定稳定</td>
</tr>
<tr>
<td>适用场景</td>
<td>相似度、检索、匹配等</td>
<td>分类、NER、QA等任务</td>
</tr>
<tr>
<td>使用方便度</td>
<td>✅ 高度封装</td>
<td>❌需要手动处理向量、聚合等</td>
</tr>
</tbody>
</table>
<h2><a id="2__23"></a>2 常用模型推荐</h2>
<table>
<thead>
<tr>
<th>模型名称</th>
<th>向量维度</th>
<th>模型大小</th>
<th>内存占用(加载后)</th>
<th>特点</th>
</tr>
</thead>
<tbody>
<tr>
<td>all-MiniLM-L6-v2</td>
<td>384</td>
<td>~80MB</td>
<td>~400MB</td>
<td>🚀 快速、轻量,适合中文和英文</td>
</tr>
<tr>
<td>paraphrase-MiniLM-L6-v2</td>
<td>384</td>
<td>~80MB</td>
<td>~400MB</td>
<td>英文表现好、语义相似度强</td>
</tr>
<tr>
<td>multi-qa-MiniLM-L6-cos-v1</td>
<td>384</td>
<td>~80MB</td>
<td>~400MB</td>
<td>多语言问答优化版本</td>
</tr>
<tr>
<td>all-mpnet-base-v2</td>
<td>768</td>
<td>~420MB</td>
<td>~1.3GB</td>
<td>精度更高,英文效果佳</td>
</tr>
<tr>
<td>paraphrase-multilingual-MiniLM-L12-v2</td>
<td>384</td>
<td>~190MB</td>
<td>~800MB</td>
<td>多语言支持(包括中文)</td>
</tr>
<tr>
<td>distiluse-base-multilingual-cased-v2</td>
<td>512</td>
<td>~230MB</td>
<td>~1GB</td>
<td>多语言支持、效果稳定</td>
</tr>
<tr>
<td>LaBSE</td>
<td>768</td>
<td>~1.3GB</td>
<td>~2.5GB</td>
<td>跨语言最佳选择(谷歌出品)</td>
</tr>
</tbody>
</table>
<p>阿里的开源模型推荐(中文向量)</p>
<table>
<thead>
<tr>
<th>模型名称</th>
<th>来源</th>
<th>向量维度</th>
<th>模型大小</th>
<th>加载内存 (CPU)</th>
<th>显存占用 (GPU)</th>
<th>特点</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>GanymedeNil/text2vec-base-chinese</strong></td>
<td>阿里达摩院&社区维护</td>
<td>768</td>
<td>~400MB</td>
<td><strong>~1.2GB</strong></td>
<td>~1.4GB</td>
<td>🔥 中文相似度表现优异,经典款</td>
</tr>
<tr>
<td><strong>shibing624/text2vec-base-multilingual</strong></td>
<td>阿里社区衍生</td>
<td>768</td>
<td>~400MB</td>
<td>~1.2GB</td>
<td>~1.4GB</td>
<td>多语言兼容(中英等)</td>
</tr>
<tr>
<td><strong>damotext/sbert-chinese-general-v2</strong></td>
<td>阿里达摩院</td>
<td>768</td>
<td>~420MB</td>
<td>~1.2GB</td>
<td>~1.4GB</td>
<td>精度高,适合通用相似度</td>
</tr>
<tr>
<td><strong>Alibaba-NLP/gte-base-zh</strong></td>
<td>阿里</td>
<td>768</td>
<td>~420MB</td>
<td>~1.2GB</td>
<td>~1.4GB</td>
<td>适合中文搜索、问答等场景</td>
</tr>
<tr>
<td><strong>damotext/bge-large-zh-v1.5</strong></td>
<td>阿里达摩院 BGE 系列</td>
<td>1024</td>
<td>~1.2GB</td>
<td><strong>~3.5GB</strong></td>
<td>~4.5GB</td>
<td>🔥 精度最强,适合召回、RAG</td>
</tr>
</tbody>
</table>
<table>
<thead>
<tr>
<th>模型名称</th>
<th>向量维度</th>
<th>模型磁盘大小</th>
<th>部署后内存占用(估算)</th>
<th>特点</th>
</tr>
</thead>
<tbody>
<tr>
<td><a href="https://huggingface.co/BAAI/bge-small-zh-v1.5" target="_blank"><code>BAAI/bge-small-zh-v1.5</code></a></td>
<td>512</td>
<td>~150MB</td>
<td>✅ <strong>≈ 700MB</strong></td>
<td>📦 轻量,适合在线部署,性能与速度平衡</td>
</tr>
<tr>
<td><a href="https://huggingface.co/BAAI/bge-base-zh-v1.5" target="_blank"><code>BAAI/bge-base-zh-v1.5</code></a></td>
<td>768</td>
<td>~400MB</td>
<td>✅ <strong>≈ 1.7GB</strong></td>
<td>🧠 通用性好,适合中等负载搜索、召回</td>
</tr>
<tr>
<td><a href="https://huggingface.co/BAAI/bge-large-zh-v1.5" target="_blank"><code>BAAI/bge-large-zh-v1.5</code></a></td>
<td>1024</td>
<td>~1.2GB</td>
<td>⚠️ <strong>≈ 4.8GB</strong></td>
<td>🚀 精度高,适合 RAG、大规模召回、问答任务</td>
</tr>
</tbody>
</table>
<h2><a id="3__51"></a>3 文本向量化案例</h2>
<pre><div class="hljs"><code class="lang-shell">sentence-transformers==4.1.0
huggingface_hub[hf_xet]
</code></div></pre>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> SentenceTransformer, util
<span class="hljs-comment"># 加载模型 </span>
model = SentenceTransformer(<span class="hljs-string">'all-MiniLM-L6-v2'</span>)
<span class="hljs-comment"># 编码两个句子为向量</span>
emb1 = model.encode(<span class="hljs-string">"你好吗?"</span>)
emb2 = model.encode(<span class="hljs-string">"你最近怎么样?"</span>)
<span class="hljs-comment"># 计算相似度(余弦相似度)</span>
similarity = util.cos_sim(emb1, emb2)
<span class="hljs-built_in">print</span>(similarity) <span class="hljs-comment"># 输出一个相似度分数(越接近 1 越相似)</span>
</code></div></pre>
<p>模型1测试</p>
<p><img src="https://www.couragesteak.com/tcos/article/c55c07934d86d999b948e66291212760.png" alt="SentenceTransformer文本向量化案例" /></p>
<p>模型2测试</p>
<p><img src="https://www.couragesteak.com/tcos/article/eff19d1ed8c905b37022697fd57abbe0.png" alt="image.png" /></p>

评论区