huggingface下载模型与加载案例
有勇气的牛排
923
AI大模型
2025-07-21 22:20:00
介绍
Hugging Face Hub 是一个平台,它旨在促进机器学习模型,特别是自然语言处理(NLP)模型的分享与协作。通过 Hugging Face Hub,研究人员和开发者能够轻松地发布他们的模型、数据集以及相关的代码,同时也能够方便地访问他人分享的资源。这个平台极大地推动了预训练模型的普及和应用,使得更多的人可以利用先进的AI技术。
官网:
https://huggingface.co/
镜像:
https://hf-mirror.com/
1 下载模型
python3.10
hf_xet==1.1.5
from huggingface_hub import snapshot_download
save_dir = "/tmp/model/all-MiniLM-L6-v2"
model_name = "sentence-transformers/all-MiniLM-L6-v2"
save_dir_new = f"{save_dir}/{model_name}"
token = None
snapshot_download(
repo_id=model_name,
local_dir=save_dir_new,
local_dir_use_symlinks=False,
token=None
)
print("模型已下载到:", save_dir)
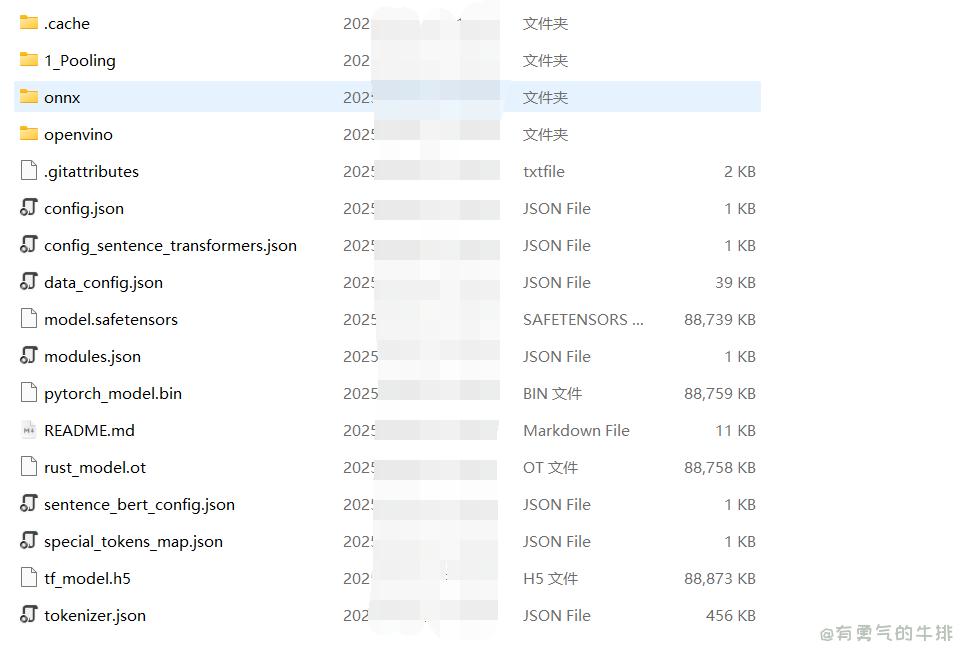
2 加载本地模型
文本向量化案例
all-MiniLM-L6-v2
from sentence_transformers import SentenceTransformer
model_path = "E:/blog_article/tmp/model/all-MiniLM-L6-v2"
model = SentenceTransformer(model_path)
sentences = [
"你好,世界!",
"这是一段用于向量化的文本。",
"机器学习正在改变世界。"
]
embeddings = model.encode(sentences)
for i, emb in enumerate(embeddings):
print(f"第{i+1}个句子向量 shape: {emb.shape}")
print(emb[:10])
<h2><a id="_0"></a>介绍</h2>
<p>Hugging Face Hub 是一个平台,它旨在促进机器学习模型,特别是自然语言处理(NLP)模型的分享与协作。通过 Hugging Face Hub,研究人员和开发者能够轻松地发布他们的模型、数据集以及相关的代码,同时也能够方便地访问他人分享的资源。这个平台极大地推动了预训练模型的普及和应用,使得更多的人可以利用先进的AI技术。</p>
<p>官网:</p>
<p><a href="https://huggingface.co/" target="_blank">https://huggingface.co/</a></p>
<p>镜像:</p>
<p><a href="https://hf-mirror.com/" target="_blank">https://hf-mirror.com/</a></p>
<h2><a id="1__12"></a>1 下载模型</h2>
<p>python3.10</p>
<pre><div class="hljs"><code class="lang-shell">hf_xet==1.1.5
</code></div></pre>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> huggingface_hub <span class="hljs-keyword">import</span> snapshot_download
<span class="hljs-comment"># import os</span>
<span class="hljs-comment"># os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"</span>
<span class="hljs-comment"># 自定义保存路径</span>
save_dir = <span class="hljs-string">"/tmp/model/all-MiniLM-L6-v2"</span>
model_name = <span class="hljs-string">"sentence-transformers/all-MiniLM-L6-v2"</span>
save_dir_new = <span class="hljs-string">f"<span class="hljs-subst">{save_dir}</span>/<span class="hljs-subst">{model_name}</span>"</span>
<span class="hljs-comment"># 设置你的 Token(推荐将其保存在环境变量或配置中)</span>
token = <span class="hljs-literal">None</span> <span class="hljs-comment"># 替换为你的实际 token : hf_xxx...</span>
<span class="hljs-comment"># 下载模型(包含 config, tokenizer, pytorch_model.bin 等)</span>
snapshot_download(
repo_id=model_name, <span class="hljs-comment"># 模型名称或路径</span>
local_dir=save_dir_new, <span class="hljs-comment"># 自定义保存路径</span>
local_dir_use_symlinks=<span class="hljs-literal">False</span>, <span class="hljs-comment"># 防止软链接,直接复制文件</span>
token=<span class="hljs-literal">None</span>
)
<span class="hljs-built_in">print</span>(<span class="hljs-string">"模型已下载到:"</span>, save_dir)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/292208ac286a3e26c441ffa2e7965969.png" alt="huggingface_hub下载模型案例" /></p>
<h2><a id="2__48"></a>2 加载本地模型</h2>
<p>文本向量化案例</p>
<p><code>all-MiniLM-L6-v2</code></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> SentenceTransformer
<span class="hljs-comment"># 模型本地路径</span>
model_path = <span class="hljs-string">"E:/blog_article/tmp/model/all-MiniLM-L6-v2"</span>
<span class="hljs-comment"># 加载模型</span>
model = SentenceTransformer(model_path)
sentences = [
<span class="hljs-string">"你好,世界!"</span>,
<span class="hljs-string">"这是一段用于向量化的文本。"</span>,
<span class="hljs-string">"机器学习正在改变世界。"</span>
]
<span class="hljs-comment"># 向量化</span>
embeddings = model.encode(sentences)
<span class="hljs-comment"># 输出向量</span>
<span class="hljs-keyword">for</span> i, emb <span class="hljs-keyword">in</span> <span class="hljs-built_in">enumerate</span>(embeddings):
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"第<span class="hljs-subst">{i+<span class="hljs-number">1</span>}</span>个句子向量 shape: <span class="hljs-subst">{emb.shape}</span>"</span>)
<span class="hljs-built_in">print</span>(emb[:<span class="hljs-number">10</span>]) <span class="hljs-comment"># 只看前10维</span>
</code></div></pre>

评论区