1 简介
LangChain 是一个用于构建基于大语言模型(LLM)应用的强大框架,它将语言模型与各种外部数据源(如向量数据库、API、搜索引擎等)结合,适合构建聊天机器人、文档问答、智能体系统(Agent)、工具调用、链式推理等AI应用。
1.1 LangChain 核心概念简介
| 模块 |
说明 |
| LLM |
接入大预言模型,如OpenA、Aliyun、ChatGLM |
| Prompt |
构建提示词模板 |
| Chains |
多步链式调用,输出作为下一个步骤输入 |
| Tools |
第三方工具、如API、搜索引擎等 |
| Agents |
动态决策调用哪些工具 |
| Memory |
会话记忆模块 |
| Vectorstore |
向量数据库,如FAISS、Milvus,用于文档问答 |
| Loaders |
文档加载器,如PDF、网页、txt、CSV等 |
1.2 环境、依赖
Python版本:Python3.10
langchain==0.3.26
requests==2.32.3
2 LLM模块(语言模型接入)
LangChain 可通过自定义 LLM 类封装任意模型,比如通义千问API。
调用通义千问案例:
封装为类:util_ali_llm.py
"""
pip install langchain requests
langchain==0.3.26
"""
from langchain_core.language_models.llms import LLM
from typing import Optional, List
import requests
class QwenLLM(LLM):
model: str = "qwen-turbo"
api_key: str = "你的阿里API Key"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
json_data = {
"model": self.model,
"input": {"prompt": prompt},
"parameters": {"result_format": "text"}
}
resp = requests.post(
url="https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation",
headers=headers,
json=json_data
).json()
return resp["output"]["text"]
@property
def _llm_type(self) -> str:
return "qwen"
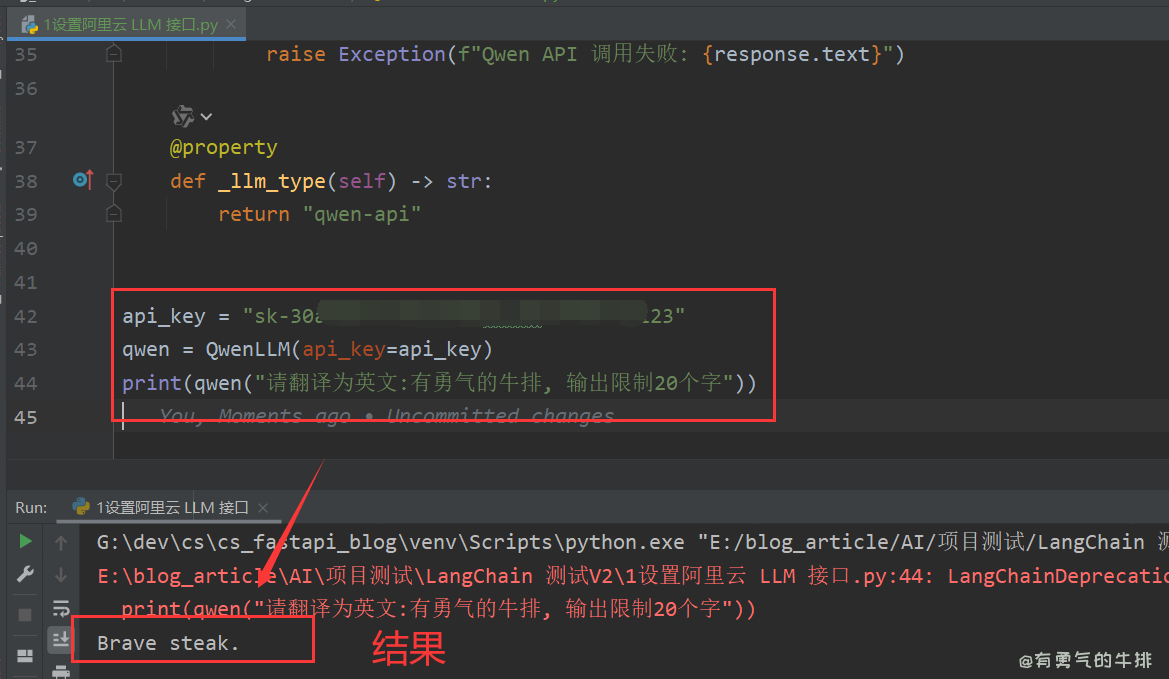
api_key = "sk-30a***123"
qwen = QwenLLM(api_key=api_key)
print(qwen("请翻译为英文:有勇气的牛排, 输出限制20个字"))
2 Prompt 模块
LangChain支持使用 PromptTemplate 定义复杂的提示词模板。
from langchain.prompts import PromptTemplate
template = """
请将输入的文本转换成中文。
输入:{user_input}
"""
prompt = PromptTemplate(template=template, input_variables=["user_input"])
user_input = "有勇气的牛排"
print(prompt.format_prompt(user_input=user_input))
3 Chains 模块
使用链(Chain)使用多个模块串联。
from util_ali_llm import QwenLLM
from langchain.prompts import PromptTemplate
from langchain_core.runnables import RunnableSequence
api_key = "sk-30a***123"
qwen_llm = QwenLLM(api_key=api_key)
template = """
请将输入的文本转换成英文。
输入:{question}
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
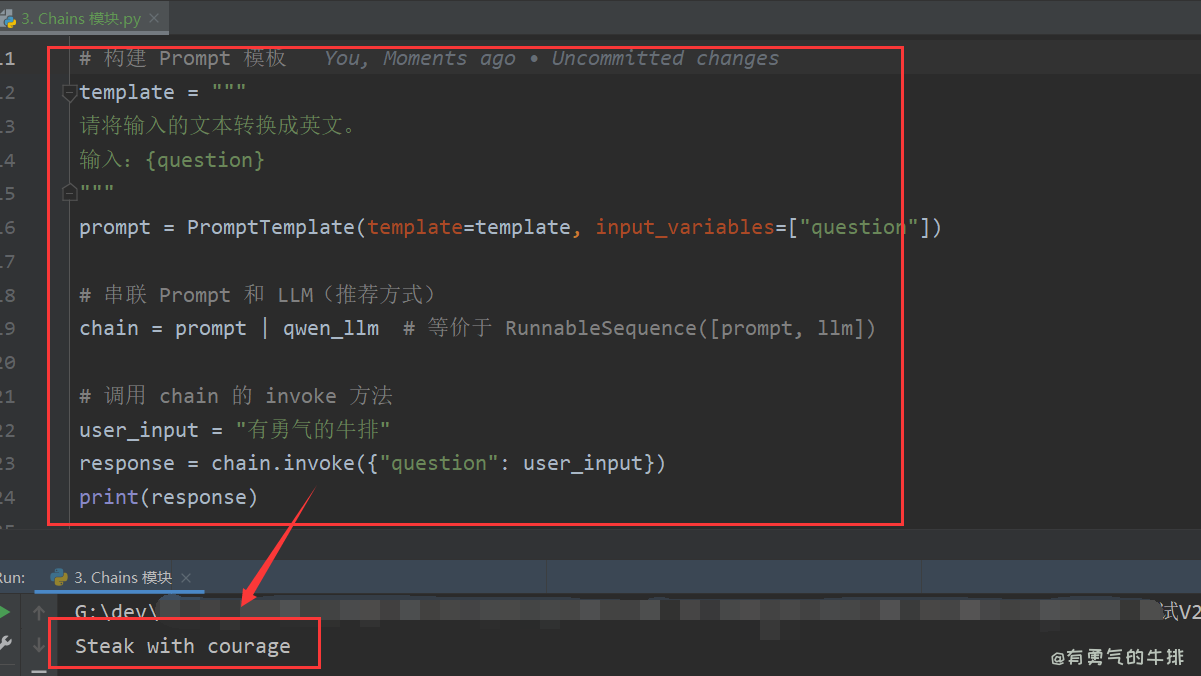
chain = prompt | qwen_llm
user_input = "有勇气的牛排"
response = chain.invoke({"question": user_input})
print(response)
4 Tools 模块
调用第三方接口,如天气、某些计算
多个 tool 工具统一封装成一个 agent-ready 的模块,例如自动识别用户输入、调用 IP 查询、天气、笑话、股票、翻译等,可无需关心内部结构。
4.1工具案例
4.1.1 计算圆的面积
calculate_area.py
from langchain.tools import tool
@tool
def calculate_area(radius: float) -> float:
"""计算圆的面积"""
import math
return round(math.pi * radius ** 2, 2)
print(calculate_area.invoke({"radius": 5}))
4.1.2 获取随机笑话
get_random_joke.py
import requests
from langchain.tools import tool
@tool
def get_random_joke() -> str:
"""获取一个随机笑话"""
url = "https://official-joke-api.appspot.com/jokes/random"
resp = requests.get(url).json()
return f"{resp['setup']} —— {resp['punchline']}"
print(get_random_joke.invoke({}))
4.2 在Agent中注册Tool
from langchain.agents import initialize_agent, AgentType, Tool
from tools.计算圆面积 import calculate_area
from tools.随机笑话 import get_random_joke
from tools.time_now import get_beijing_time
from util_ali_llm import QwenLLM
api_key = "sk-30a***123"
qwen_llm = QwenLLM(api_key=api_key)
tools = [
Tool(name="Calculator", func=calculate_area.run, description="获取圆的面积"),
Tool(name="Joke", func=get_random_joke.run, description="获取圆的面积", ),
Tool(name="TimeTool", func=get_beijing_time.run, description="获取北京时间", ),
]
agent = initialize_agent(
tools, qwen_llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
agent.run("给我讲个笑话")
4.3 工具统一注册
from tools.ip_location import get_ip_location
from tools.joke import get_joke
from tools.time_now import get_beijing_time
from tools.math_tools import calculate_circle_area
ALL_TOOLS = [
get_ip_location,
get_joke,
get_beijing_time,
calculate_circle_area
]
Agent 主程序(main.py)
from tools import ALL_TOOLS
from util_ali_llm import QwenLLM
from langchain.agents import initialize_agent, AgentType
if __name__ == "__main__":
llm = QwenLLM()
agent = initialize_agent(
tools=ALL_TOOLS,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
while True:
query = input("你想问什么?(输入exit退出)\n> ")
if query.lower() in {"exit", "quit"}:
break
result = agent.invoke(query)
print("🤖", result)
5 Agent 模块
Agent 可根据输入智能决定调用哪些工具
from langchain.agents import initialize_agent, AgentType
from langchain.agents import Tool
tools = [
Tool(name="AliWeather", func=ali_weather.run, description="获取指定城市的天气")
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("请告诉我今天北京的天气")
6 记忆会话功能
6.1 为每个用户单独创建一份 Memory 实例
每个用户维护独立的 ConversationChain 或 memory 实例,例如用一个字典来存储
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
from util_ali_llm import QwenLLM
api_key = "sk-30a***123"
qwen_llm = QwenLLM(api_key=api_key)
user_sessions = {}
def get_user_chain(user_id):
if user_id not in user_sessions:
memory = ConversationBufferMemory()
chain = ConversationChain(llm=qwen_llm, memory=memory)
user_sessions[user_id] = chain
return user_sessions[user_id]
user_id = "user_001"
chain = get_user_chain(user_id)
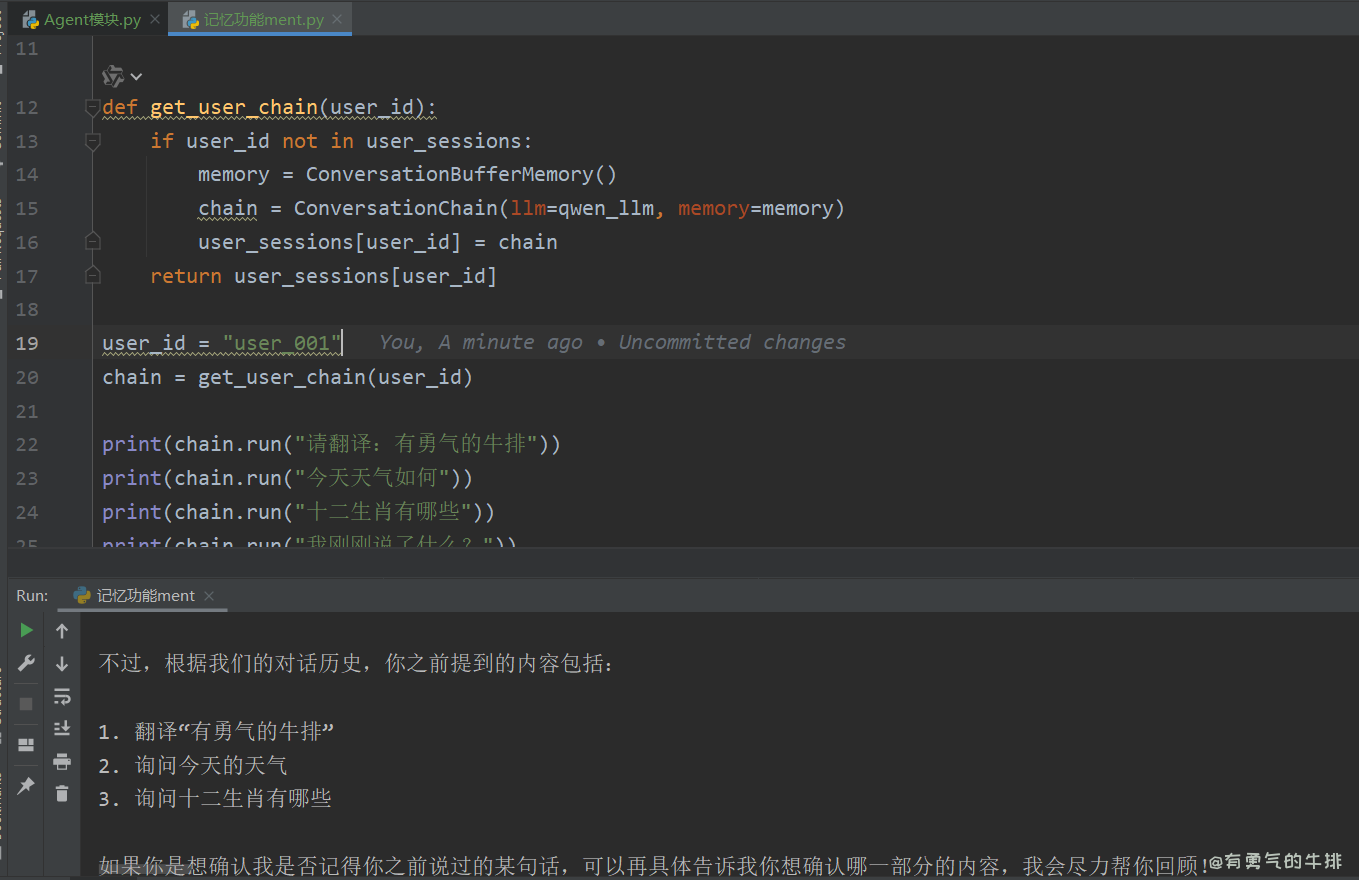
print(chain.run("请翻译:有勇气的牛排"))
print(chain.run("今天天气如何"))
print(chain.run("十二生肖有哪些"))
print(chain.run("我刚刚说了什么?"))
print(user_sessions)
6.2 方法二:使用「向量记忆 + 用户ID过滤」
方案(用于长期存储)
7. VectorStore 模块(文档问答)
文档向量化后可用于语义检索。
加载文本 + FAISS 构建知识库 + 问答
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
loader = TextLoader("阿里介绍.txt", encoding="utf-8")
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100)
split_docs = text_splitter.split_documents(docs)
embedding = HuggingFaceEmbeddings(model_name="shibing624/text2vec-base-chinese")
db = FAISS.from_documents(split_docs, embedding)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
print(qa.run("阿里的主营业务是什么?"))
8 总结
| 模块 |
案例 |
用途 |
| LLM |
接入通义千问 |
语言模型问答 |
| Prompt |
自定义提示词 |
控制输出风格 |
| Chain |
LLM链 |
串联多个组件处理逻辑 |
| Tool |
阿里天气 |
对外接口封装 |
| Agent |
自主调用工具 |
构建多工具智能体 |
| Memory |
聊天记忆 |
上下文连续对话 |
| VectorDB |
阿里介绍文档 |
文档问答、企业知识库系统 |
<h2><a id="1__0"></a>1 简介</h2>
<p>LangChain 是一个用于构建基于大语言模型(LLM)应用的强大框架,它将语言模型与各种外部数据源(如向量数据库、API、搜索引擎等)结合,适合构建聊天机器人、文档问答、智能体系统(Agent)、工具调用、链式推理等AI应用。</p>
<h3><a id="11_LangChain__4"></a>1.1 LangChain 核心概念简介</h3>
<table>
<thead>
<tr>
<th>模块</th>
<th>说明</th>
</tr>
</thead>
<tbody>
<tr>
<td>LLM</td>
<td>接入大预言模型,如OpenA、Aliyun、ChatGLM</td>
</tr>
<tr>
<td>Prompt</td>
<td>构建提示词模板</td>
</tr>
<tr>
<td>Chains</td>
<td>多步链式调用,输出作为下一个步骤输入</td>
</tr>
<tr>
<td>Tools</td>
<td>第三方工具、如API、搜索引擎等</td>
</tr>
<tr>
<td>Agents</td>
<td>动态决策调用哪些工具</td>
</tr>
<tr>
<td>Memory</td>
<td>会话记忆模块</td>
</tr>
<tr>
<td>Vectorstore</td>
<td>向量数据库,如FAISS、Milvus,用于文档问答</td>
</tr>
<tr>
<td>Loaders</td>
<td>文档加载器,如PDF、网页、txt、CSV等</td>
</tr>
</tbody>
</table>
<h3><a id="12__17"></a>1.2 环境、依赖</h3>
<p>Python版本:Python3.10</p>
<pre><div class="hljs"><code class="lang-shell">langchain==0.3.26
requests==2.32.3
</code></div></pre>
<h2><a id="2_LLM_26"></a>2 LLM模块(语言模型接入)</h2>
<p>LangChain 可通过自定义 LLM 类封装任意模型,比如通义千问API。</p>
<p>调用通义千问案例:</p>
<p>封装为类:<code>util_ali_llm.py</code></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-string">"""
pip install langchain requests
langchain==0.3.26
"""</span>
<span class="hljs-keyword">from</span> langchain_core.language_models.llms <span class="hljs-keyword">import</span> LLM
<span class="hljs-keyword">from</span> typing <span class="hljs-keyword">import</span> <span class="hljs-type">Optional</span>, <span class="hljs-type">List</span>
<span class="hljs-keyword">import</span> requests
<span class="hljs-keyword">class</span> <span class="hljs-title class_">QwenLLM</span>(<span class="hljs-title class_ inherited__">LLM</span>):
model: <span class="hljs-built_in">str</span> = <span class="hljs-string">"qwen-turbo"</span>
api_key: <span class="hljs-built_in">str</span> = <span class="hljs-string">"你的阿里API Key"</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">_call</span>(<span class="hljs-params">self, prompt: <span class="hljs-built_in">str</span>, stop: <span class="hljs-type">Optional</span>[<span class="hljs-type">List</span>[<span class="hljs-built_in">str</span>]] = <span class="hljs-literal">None</span></span>) -> <span class="hljs-built_in">str</span>:
headers = {
<span class="hljs-string">"Authorization"</span>: <span class="hljs-string">f"Bearer <span class="hljs-subst">{self.api_key}</span>"</span>,
<span class="hljs-string">"Content-Type"</span>: <span class="hljs-string">"application/json"</span>
}
json_data = {
<span class="hljs-string">"model"</span>: self.model,
<span class="hljs-string">"input"</span>: {<span class="hljs-string">"prompt"</span>: prompt},
<span class="hljs-string">"parameters"</span>: {<span class="hljs-string">"result_format"</span>: <span class="hljs-string">"text"</span>}
}
resp = requests.post(
url=<span class="hljs-string">"https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"</span>,
headers=headers,
json=json_data
).json()
<span class="hljs-keyword">return</span> resp[<span class="hljs-string">"output"</span>][<span class="hljs-string">"text"</span>]
<span class="hljs-meta"> @property</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">_llm_type</span>(<span class="hljs-params">self</span>) -> <span class="hljs-built_in">str</span>:
<span class="hljs-keyword">return</span> <span class="hljs-string">"qwen"</span>
api_key = <span class="hljs-string">"sk-30a***123"</span>
qwen = QwenLLM(api_key=api_key)
<span class="hljs-built_in">print</span>(qwen(<span class="hljs-string">"请翻译为英文:有勇气的牛排, 输出限制20个字"</span>))
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/23e86238fc8258e37655a19ff5cd43ac.png" alt="LangChain 可通过自定义 LLM 类封装任意模型,比如通义千问API。" /></p>
<h2><a id="2_Prompt__79"></a>2 Prompt 模块</h2>
<p>LangChain支持使用 <code>PromptTemplate</code> 定义复杂的提示词模板。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> langchain.prompts <span class="hljs-keyword">import</span> PromptTemplate
template = <span class="hljs-string">"""
请将输入的文本转换成中文。
输入:{user_input}
"""</span>
prompt = PromptTemplate(template=template, input_variables=[<span class="hljs-string">"user_input"</span>])
user_input = <span class="hljs-string">"有勇气的牛排"</span>
<span class="hljs-built_in">print</span>(prompt.format_prompt(user_input=user_input))
</code></div></pre>
<h2><a id="3_Chains__100"></a>3 Chains 模块</h2>
<p>使用链(Chain)使用多个模块串联。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> util_ali_llm <span class="hljs-keyword">import</span> QwenLLM
<span class="hljs-keyword">from</span> langchain.prompts <span class="hljs-keyword">import</span> PromptTemplate
<span class="hljs-keyword">from</span> langchain_core.runnables <span class="hljs-keyword">import</span> RunnableSequence <span class="hljs-comment"># 新版链式执行推荐</span>
<span class="hljs-comment"># 或者 from langchain.schema.runnable import RunnableSequence 取决于你的版本</span>
<span class="hljs-comment"># 初始化 LLM</span>
api_key = <span class="hljs-string">"sk-30a***123"</span>
qwen_llm = QwenLLM(api_key=api_key)
<span class="hljs-comment"># 构建 Prompt 模板</span>
template = <span class="hljs-string">"""
请将输入的文本转换成英文。
输入:{question}
"""</span>
prompt = PromptTemplate(template=template, input_variables=[<span class="hljs-string">"question"</span>])
<span class="hljs-comment"># 串联 Prompt 和 LLM(推荐方式)</span>
chain = prompt | qwen_llm <span class="hljs-comment"># 等价于 RunnableSequence([prompt, llm])</span>
<span class="hljs-comment"># 调用 chain 的 invoke 方法</span>
user_input = <span class="hljs-string">"有勇气的牛排"</span>
response = chain.invoke({<span class="hljs-string">"question"</span>: user_input})
<span class="hljs-built_in">print</span>(response)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/8f5c760adbbc6ba0b2de9a529d883bb0.png" alt="image.png" /></p>
<h2><a id="4_Tools__136"></a>4 Tools 模块</h2>
<p>调用第三方接口,如天气、某些计算</p>
<p>多个 <code>tool</code> 工具统一封装成一个 agent-ready 的模块,例如自动识别用户输入、调用 IP 查询、天气、笑话、股票、翻译等,可无需关心内部结构。</p>
<h3><a id="41_142"></a>4.1工具案例</h3>
<h4><a id="411__144"></a>4.1.1 计算圆的面积</h4>
<p><code>calculate_area.py</code></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain.tools <span class="hljs-keyword">import</span> tool
<span class="hljs-meta">@tool</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">calculate_area</span>(<span class="hljs-params">radius: <span class="hljs-built_in">float</span></span>) -> <span class="hljs-built_in">float</span>:
<span class="hljs-string">"""计算圆的面积"""</span>
<span class="hljs-keyword">import</span> math
<span class="hljs-keyword">return</span> <span class="hljs-built_in">round</span>(math.pi * radius ** <span class="hljs-number">2</span>, <span class="hljs-number">2</span>)
<span class="hljs-built_in">print</span>(calculate_area.invoke({<span class="hljs-string">"radius"</span>: <span class="hljs-number">5</span>}))
</code></div></pre>
<h4><a id="412__160"></a>4.1.2 获取随机笑话</h4>
<p><code>get_random_joke.py</code></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> requests
<span class="hljs-keyword">from</span> langchain.tools <span class="hljs-keyword">import</span> tool
<span class="hljs-meta">@tool</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">get_random_joke</span>() -> <span class="hljs-built_in">str</span>:
<span class="hljs-string">"""获取一个随机笑话"""</span>
url = <span class="hljs-string">"https://official-joke-api.appspot.com/jokes/random"</span>
resp = requests.get(url).json()
<span class="hljs-keyword">return</span> <span class="hljs-string">f"<span class="hljs-subst">{resp[<span class="hljs-string">'setup'</span>]}</span> —— <span class="hljs-subst">{resp[<span class="hljs-string">'punchline'</span>]}</span>"</span>
<span class="hljs-comment"># 测试</span>
<span class="hljs-built_in">print</span>(get_random_joke.invoke({}))
</code></div></pre>
<h3><a id="42_AgentTool_179"></a>4.2 在Agent中注册Tool</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> langchain.agents <span class="hljs-keyword">import</span> initialize_agent, AgentType, Tool
<span class="hljs-keyword">from</span> tools.计算圆面积 <span class="hljs-keyword">import</span> calculate_area
<span class="hljs-keyword">from</span> tools.随机笑话 <span class="hljs-keyword">import</span> get_random_joke
<span class="hljs-keyword">from</span> tools.time_now <span class="hljs-keyword">import</span> get_beijing_time
<span class="hljs-keyword">from</span> util_ali_llm <span class="hljs-keyword">import</span> QwenLLM
<span class="hljs-comment"># 初始化 LLM</span>
api_key = <span class="hljs-string">"sk-30a***123"</span>
qwen_llm = QwenLLM(api_key=api_key)
tools = [
Tool(name=<span class="hljs-string">"Calculator"</span>, func=calculate_area.run, description=<span class="hljs-string">"获取圆的面积"</span>),
Tool(name=<span class="hljs-string">"Joke"</span>, func=get_random_joke.run, description=<span class="hljs-string">"获取圆的面积"</span>, ),
Tool(name=<span class="hljs-string">"TimeTool"</span>, func=get_beijing_time.run, description=<span class="hljs-string">"获取北京时间"</span>, ),
]
<span class="hljs-comment"># 初始化Agent</span>
agent = initialize_agent(
tools, qwen_llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=<span class="hljs-literal">True</span>,
handle_parsing_errors=<span class="hljs-literal">True</span> <span class="hljs-comment"># 当 LLM 输出格式混乱时,自动 Retry 而不是直接报错。</span>
)
<span class="hljs-comment"># 调用示例</span>
<span class="hljs-comment"># print(agent.run("请告诉我现在的北京时间"))</span>
<span class="hljs-comment"># print(agent.run("请计算圆半径为5m的面积"))</span>
<span class="hljs-comment"># print("=============")</span>
agent.run(<span class="hljs-string">"给我讲个笑话"</span>)
<span class="hljs-comment"># print(f"res: {res}")</span>
</code></div></pre>
<h3><a id="43__216"></a>4.3 工具统一注册</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> tools.ip_location <span class="hljs-keyword">import</span> get_ip_location
<span class="hljs-keyword">from</span> tools.joke <span class="hljs-keyword">import</span> get_joke
<span class="hljs-keyword">from</span> tools.time_now <span class="hljs-keyword">import</span> get_beijing_time
<span class="hljs-keyword">from</span> tools.math_tools <span class="hljs-keyword">import</span> calculate_circle_area
ALL_TOOLS = [
get_ip_location,
get_joke,
get_beijing_time,
calculate_circle_area
]
</code></div></pre>
<h3><a id="Agent_mainpy_232"></a>Agent 主程序(<code>main.py</code>)</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> tools <span class="hljs-keyword">import</span> ALL_TOOLS
<span class="hljs-keyword">from</span> util_ali_llm <span class="hljs-keyword">import</span> QwenLLM
<span class="hljs-keyword">from</span> langchain.agents <span class="hljs-keyword">import</span> initialize_agent, AgentType
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>:
llm = QwenLLM()
agent = initialize_agent(
tools=ALL_TOOLS,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=<span class="hljs-literal">True</span>
)
<span class="hljs-keyword">while</span> <span class="hljs-literal">True</span>:
query = <span class="hljs-built_in">input</span>(<span class="hljs-string">"你想问什么?(输入exit退出)\n> "</span>)
<span class="hljs-keyword">if</span> query.lower() <span class="hljs-keyword">in</span> {<span class="hljs-string">"exit"</span>, <span class="hljs-string">"quit"</span>}:
<span class="hljs-keyword">break</span>
result = agent.invoke(query)
<span class="hljs-built_in">print</span>(<span class="hljs-string">"🤖"</span>, result)
</code></div></pre>
<h2><a id="5_Agent__257"></a>5 Agent 模块</h2>
<p>Agent 可根据输入智能决定调用哪些工具</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain.agents <span class="hljs-keyword">import</span> initialize_agent, AgentType
<span class="hljs-keyword">from</span> langchain.agents <span class="hljs-keyword">import</span> Tool
tools = [
Tool(name=<span class="hljs-string">"AliWeather"</span>, func=ali_weather.run, description=<span class="hljs-string">"获取指定城市的天气"</span>)
]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=<span class="hljs-literal">True</span>)
agent.run(<span class="hljs-string">"请告诉我今天北京的天气"</span>)
</code></div></pre>
<h2><a id="6__277"></a>6 记忆会话功能</h2>
<h3><a id="61__Memory__279"></a>6.1 为每个用户单独创建一份 Memory 实例</h3>
<p>每个用户维护独立的 <code>ConversationChain</code> 或 <code>memory</code> 实例,例如用一个字典来存储</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain.memory <span class="hljs-keyword">import</span> ConversationBufferMemory
<span class="hljs-keyword">from</span> langchain.chains <span class="hljs-keyword">import</span> ConversationChain
<span class="hljs-keyword">from</span> util_ali_llm <span class="hljs-keyword">import</span> QwenLLM
<span class="hljs-comment"># 初始化 LLM</span>
api_key = <span class="hljs-string">"sk-30a***123"</span>
qwen_llm = QwenLLM(api_key=api_key)
<span class="hljs-comment"># 模拟用户会话池</span>
user_sessions = {}
<span class="hljs-keyword">def</span> <span class="hljs-title function_">get_user_chain</span>(<span class="hljs-params">user_id</span>):
<span class="hljs-keyword">if</span> user_id <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> user_sessions:
memory = ConversationBufferMemory()
chain = ConversationChain(llm=qwen_llm, memory=memory)
user_sessions[user_id] = chain
<span class="hljs-keyword">return</span> user_sessions[user_id]
user_id = <span class="hljs-string">"user_001"</span>
chain = get_user_chain(user_id)
<span class="hljs-built_in">print</span>(chain.run(<span class="hljs-string">"请翻译:有勇气的牛排"</span>))
<span class="hljs-built_in">print</span>(chain.run(<span class="hljs-string">"今天天气如何"</span>))
<span class="hljs-built_in">print</span>(chain.run(<span class="hljs-string">"十二生肖有哪些"</span>))
<span class="hljs-built_in">print</span>(chain.run(<span class="hljs-string">"我刚刚说了什么?"</span>))
<span class="hljs-built_in">print</span>(user_sessions)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/cfbb126a4e52baa52dd4fc151b64e1f3.png" alt="image.png" /></p>
<h3><a id="62___ID_318"></a>6.2 方法二:使用「向量记忆 + 用户ID过滤」</h3>
<p>方案(用于长期存储)</p>
<h2><a id="7_VectorStore__322"></a>7. VectorStore 模块(文档问答)</h2>
<p>文档向量化后可用于语义检索。</p>
<p>加载文本 + FAISS 构建知识库 + 问答</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain.vectorstores <span class="hljs-keyword">import</span> FAISS
<span class="hljs-keyword">from</span> langchain.embeddings <span class="hljs-keyword">import</span> HuggingFaceEmbeddings
<span class="hljs-keyword">from</span> langchain.text_splitter <span class="hljs-keyword">import</span> CharacterTextSplitter
<span class="hljs-keyword">from</span> langchain.document_loaders <span class="hljs-keyword">import</span> TextLoader
<span class="hljs-keyword">from</span> langchain.chains <span class="hljs-keyword">import</span> RetrievalQA
<span class="hljs-comment"># 文本加载</span>
loader = TextLoader(<span class="hljs-string">"阿里介绍.txt"</span>, encoding=<span class="hljs-string">"utf-8"</span>)
docs = loader.load()
<span class="hljs-comment"># 分词</span>
text_splitter = CharacterTextSplitter(chunk_size=<span class="hljs-number">500</span>, chunk_overlap=<span class="hljs-number">100</span>)
split_docs = text_splitter.split_documents(docs)
<span class="hljs-comment"># 嵌入模型</span>
embedding = HuggingFaceEmbeddings(model_name=<span class="hljs-string">"shibing624/text2vec-base-chinese"</span>)
db = FAISS.from_documents(split_docs, embedding)
<span class="hljs-comment"># 构建问答链</span>
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
<span class="hljs-built_in">print</span>(qa.run(<span class="hljs-string">"阿里的主营业务是什么?"</span>))
</code></div></pre>
<h2><a id="8__354"></a>8 总结</h2>
<table>
<thead>
<tr>
<th>模块</th>
<th>案例</th>
<th>用途</th>
</tr>
</thead>
<tbody>
<tr>
<td>LLM</td>
<td>接入通义千问</td>
<td>语言模型问答</td>
</tr>
<tr>
<td>Prompt</td>
<td>自定义提示词</td>
<td>控制输出风格</td>
</tr>
<tr>
<td>Chain</td>
<td>LLM链</td>
<td>串联多个组件处理逻辑</td>
</tr>
<tr>
<td>Tool</td>
<td>阿里天气</td>
<td>对外接口封装</td>
</tr>
<tr>
<td>Agent</td>
<td>自主调用工具</td>
<td>构建多工具智能体</td>
</tr>
<tr>
<td>Memory</td>
<td>聊天记忆</td>
<td>上下文连续对话</td>
</tr>
<tr>
<td>VectorDB</td>
<td>阿里介绍文档</td>
<td>文档问答、企业知识库系统</td>
</tr>
</tbody>
</table>

评论区