自定义大模型训练 监督微调SFT
有勇气的牛排
2138
AI大模型
2025-04-20 19:56:19
1 前言
1.1 定义
SFT 是Supervised Fine-Tuning 的缩写,中文叫做监督微调。它是大模型训练过程中一个关键的阶段,特别是在RLHF(人类反馈强化学习)流程中是第一步。
1.2 SFT 和预训练的区别
| 项目 |
预训练(Pretraining) |
监督微调(SFT) |
| 数据 |
大量互联网上抓取的未标注文本 |
人工标注回答、对话等结构化数据 |
| 目标 |
学习通用语言能力、知识、语法 |
学习具体任务(如回答、摘要、翻译) |
| 模型输入 |
连贯文本 |
任务指令+问题(Prompt) |
| 学习方式 |
自监督(填空、预测下一个词) |
监督学习(有明确标签/答案) |
1.3 SFT 的作用
1、让大模型更擅长听指令。
例如:“请写一篇关于保护环境的演讲稿”,这样模型可以知道这是指令,而不是对话。
2、帮助模型适应下游任务。
例如:摘要、翻译、问答、代码生成、法律文书撰写等。
3、打基础,为RLHF 做准备。
没有SFT、RLHF的奖励模型和策略优化,肯呢个收敛很慢,甚至失败。
2 依赖
requirements.txt
# Core
transformers>=4.36.0
datasets>=2.14.0
torch==2.3.1
# 可选:低资源训练支持(LoRA、量化等)
peft>=0.7.1
accelerate>=0.24.0
bitsandbytes>=0.41.0 # 仅限 GPU,CPU 会报错
# 中文支持模型可能需要
sentencepiece>=0.1.99
protobuf<4.0.0 # 防止模型加载出错
# 用于格式化进度条、日志等
tqdm
如需只在 CPU 上训练,可以手动移除或注释掉:
bitsandbytes>=0.41.0
手动安装
pip install torch==2.3.1 torchvision==0.18.1+cu121 torchaudio==2.3.1+cu121 --index-url https://download.pytorch.org/whl/cu121
2 训练数据
生成模拟数据脚本
import json
import random
characters = [
"韩立", "墨大夫", "紫灵", "李慕白", "莫倾城", "楚风",
"柳如烟", "剑宗掌门", "江尘", "林清", "沈墨", "苏璃",
"周天", "谢灵涯", "唐昊", "萧炎", "白浅", "夜华",
"凤九", "东皇太一"
]
relations = [
"夫妻", "师徒", "恋人", "敌对", "父女", "师兄弟", "好友", "师妹",
"师姐", "师傅", "师尊", "同门", "情敌", "师父", "徒弟", "战友",
"师叔", "师伯", "师姑", "父子", "母子", "兄弟", "姐妹"
]
def gen_sentence(c1, c2, rel):
templates = [
f"{c1}与{c2}是{rel}关系。",
f"{c1}是{c2}的{rel}。",
f"{c2}一直深爱着{c1},两人是{rel}。",
f"{c1}和{c2}关系复杂,既是{rel},又有矛盾。",
f"{c1}收{c2}为徒弟,师徒关系牢固。",
f"{c1}与{c2}情同手足,是{rel}。",
f"{c1}深爱着{c2},两人结为{rel}。",
f"{c1}和{c2}曾是{rel}。"
]
return random.choice(templates)
def gen_input_output():
n = random.randint(1, 3)
chosen = random.sample(relations, n)
chosen_chars = random.sample(characters, n * 2)
input_sentences = []
output_lines = []
for i in range(n):
c1 = chosen_chars[2 * i]
c2 = chosen_chars[2 * i + 1]
rel = chosen[i]
input_sentences.append(gen_sentence(c1, c2, rel))
output_lines.append(f"{c1}-{c2}:{rel}")
instruction = "从以下小说内容中提取人物关系:" + " ".join(input_sentences)
return {
"instruction": instruction,
"input": "",
"output": "\n".join(output_lines)
}
data = [gen_input_output() for _ in range(100)]
with open("rel.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("✅ 已生成1000条小说人物关系训练数据,保存在 rel_1000.json")
[
{
"instruction": "从以下小说内容中提取人物关系:柳如烟是凤九的情敌。 江尘一直深爱着林清,两人是师尊。 东皇太一和沈墨曾是徒弟。",
"input": "",
"output": "柳如烟-凤九:情敌\n林清-江尘:师尊\n东皇太一-沈墨:徒弟"
},
{
"instruction": "从以下小说内容中提取人物关系:楚风一直深爱着凤九,两人是师伯。 莫倾城与柳如烟是母子关系。",
"input": "",
"output": "凤九-楚风:师伯\n莫倾城-柳如烟:母子"
},
{
"instruction": "从以下小说内容中提取人物关系:李慕白一直深爱着莫倾城,两人是战友。 东皇太一与柳如烟情同手足,是父子。",
"input": "",
"output": "莫倾城-李慕白:战友\n东皇太一-柳如烟:父子"
}
...
]
2 训练代码
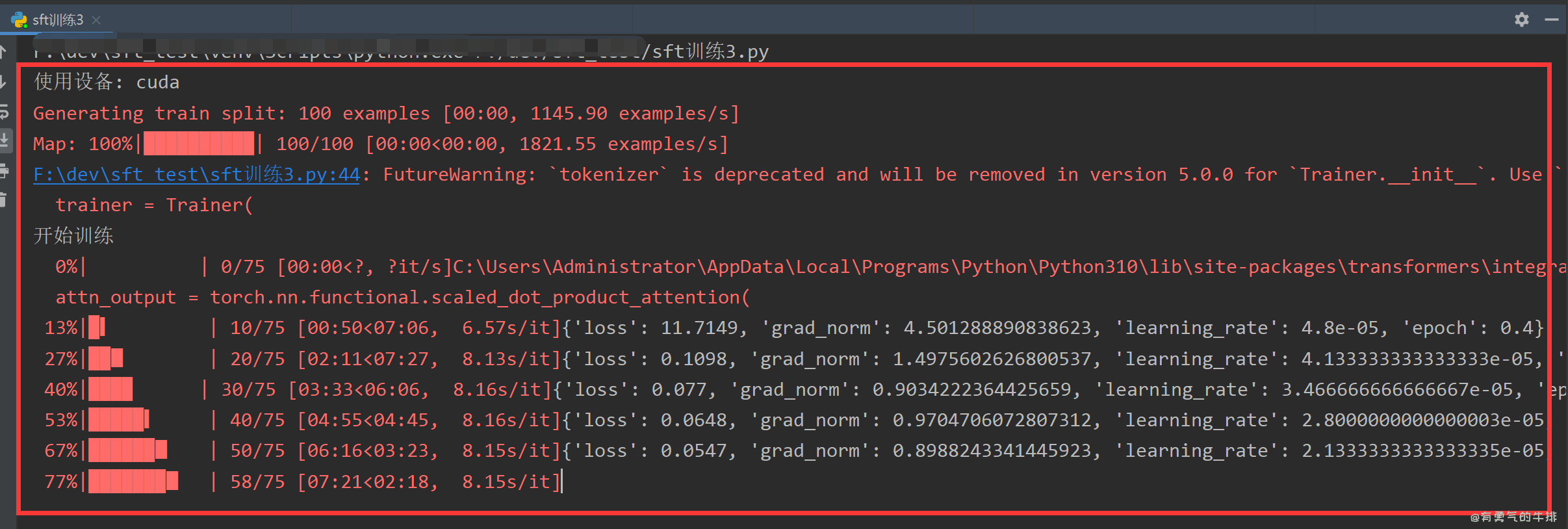
3 调用模型
3.1 单次调用
3.2 流式调用
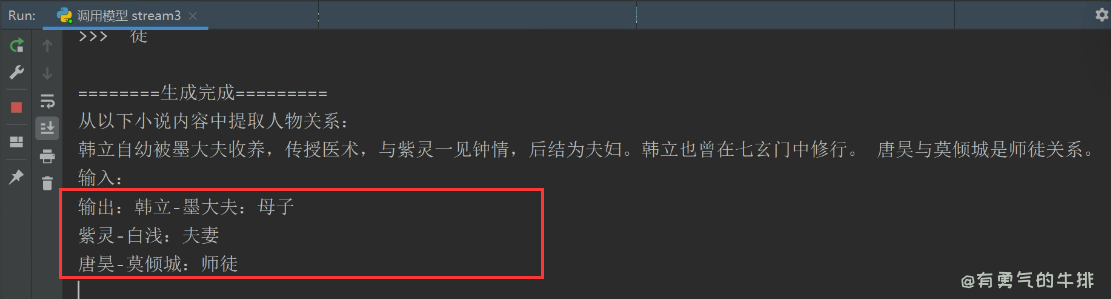
<h2><a id="1__0"></a>1 前言</h2>
<h3><a id="11__2"></a>1.1 定义</h3>
<p>SFT 是Supervised Fine-Tuning 的缩写,中文叫做监督微调。它是大模型训练过程中一个关键的阶段,特别是在RLHF(人类反馈强化学习)流程中是第一步。</p>
<h3><a id="12_SFT__6"></a>1.2 SFT 和预训练的区别</h3>
<table>
<thead>
<tr>
<th>项目</th>
<th>预训练(Pretraining)</th>
<th>监督微调(SFT)</th>
</tr>
</thead>
<tbody>
<tr>
<td>数据</td>
<td>大量互联网上抓取的未标注文本</td>
<td>人工标注回答、对话等结构化数据</td>
</tr>
<tr>
<td>目标</td>
<td>学习通用语言能力、知识、语法</td>
<td>学习具体任务(如回答、摘要、翻译)</td>
</tr>
<tr>
<td>模型输入</td>
<td>连贯文本</td>
<td>任务指令+问题(Prompt)</td>
</tr>
<tr>
<td>学习方式</td>
<td>自监督(填空、预测下一个词)</td>
<td>监督学习(有明确标签/答案)</td>
</tr>
</tbody>
</table>
<h3><a id="13__SFT__15"></a>1.3 SFT 的作用</h3>
<p>1、让大模型更擅长听指令。</p>
<p> 例如:“请写一篇关于保护环境的演讲稿”,这样模型可以知道这是指令,而不是对话。</p>
<p>2、帮助模型适应下游任务。</p>
<p> 例如:摘要、翻译、问答、代码生成、法律文书撰写等。</p>
<p>3、打基础,为RLHF 做准备。</p>
<p> 没有SFT、RLHF的奖励模型和策略优化,肯呢个收敛很慢,甚至失败。</p>
<h2><a id="2__29"></a>2 依赖</h2>
<p><code>requirements.txt</code></p>
<pre><div class="hljs"><code class="lang-txt"># Core
transformers>=4.36.0
datasets>=2.14.0
torch==2.3.1
# 可选:低资源训练支持(LoRA、量化等)
peft>=0.7.1
accelerate>=0.24.0
bitsandbytes>=0.41.0 # 仅限 GPU,CPU 会报错
# 中文支持模型可能需要
sentencepiece>=0.1.99
protobuf<4.0.0 # 防止模型加载出错
# 用于格式化进度条、日志等
tqdm
</code></div></pre>
<p>如需只在 <strong>CPU 上训练</strong>,可以手动移除或注释掉:</p>
<pre><code class="lang-">bitsandbytes>=0.41.0
</code></pre>
<p>手动安装</p>
<pre><div class="hljs"><code class="lang-shell">pip install torch==2.3.1 torchvision==0.18.1+cu121 torchaudio==2.3.1+cu121 --index-url https://download.pytorch.org/whl/cu121
</code></div></pre>
<h2><a id="2__64"></a>2 训练数据</h2>
<p>生成模拟数据脚本</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> json
<span class="hljs-keyword">import</span> random
<span class="hljs-comment"># 示例人物和关系</span>
characters = [
<span class="hljs-string">"韩立"</span>, <span class="hljs-string">"墨大夫"</span>, <span class="hljs-string">"紫灵"</span>, <span class="hljs-string">"李慕白"</span>, <span class="hljs-string">"莫倾城"</span>, <span class="hljs-string">"楚风"</span>,
<span class="hljs-string">"柳如烟"</span>, <span class="hljs-string">"剑宗掌门"</span>, <span class="hljs-string">"江尘"</span>, <span class="hljs-string">"林清"</span>, <span class="hljs-string">"沈墨"</span>, <span class="hljs-string">"苏璃"</span>,
<span class="hljs-string">"周天"</span>, <span class="hljs-string">"谢灵涯"</span>, <span class="hljs-string">"唐昊"</span>, <span class="hljs-string">"萧炎"</span>, <span class="hljs-string">"白浅"</span>, <span class="hljs-string">"夜华"</span>,
<span class="hljs-string">"凤九"</span>, <span class="hljs-string">"东皇太一"</span>
]
relations = [
<span class="hljs-string">"夫妻"</span>, <span class="hljs-string">"师徒"</span>, <span class="hljs-string">"恋人"</span>, <span class="hljs-string">"敌对"</span>, <span class="hljs-string">"父女"</span>, <span class="hljs-string">"师兄弟"</span>, <span class="hljs-string">"好友"</span>, <span class="hljs-string">"师妹"</span>,
<span class="hljs-string">"师姐"</span>, <span class="hljs-string">"师傅"</span>, <span class="hljs-string">"师尊"</span>, <span class="hljs-string">"同门"</span>, <span class="hljs-string">"情敌"</span>, <span class="hljs-string">"师父"</span>, <span class="hljs-string">"徒弟"</span>, <span class="hljs-string">"战友"</span>,
<span class="hljs-string">"师叔"</span>, <span class="hljs-string">"师伯"</span>, <span class="hljs-string">"师姑"</span>, <span class="hljs-string">"父子"</span>, <span class="hljs-string">"母子"</span>, <span class="hljs-string">"兄弟"</span>, <span class="hljs-string">"姐妹"</span>
]
<span class="hljs-comment"># 随机关系句模板生成</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">gen_sentence</span>(<span class="hljs-params">c1, c2, rel</span>):
templates = [
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>与<span class="hljs-subst">{c2}</span>是<span class="hljs-subst">{rel}</span>关系。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>是<span class="hljs-subst">{c2}</span>的<span class="hljs-subst">{rel}</span>。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c2}</span>一直深爱着<span class="hljs-subst">{c1}</span>,两人是<span class="hljs-subst">{rel}</span>。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>和<span class="hljs-subst">{c2}</span>关系复杂,既是<span class="hljs-subst">{rel}</span>,又有矛盾。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>收<span class="hljs-subst">{c2}</span>为徒弟,师徒关系牢固。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>与<span class="hljs-subst">{c2}</span>情同手足,是<span class="hljs-subst">{rel}</span>。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>深爱着<span class="hljs-subst">{c2}</span>,两人结为<span class="hljs-subst">{rel}</span>。"</span>,
<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>和<span class="hljs-subst">{c2}</span>曾是<span class="hljs-subst">{rel}</span>。"</span>
]
<span class="hljs-keyword">return</span> random.choice(templates)
<span class="hljs-comment"># 构造一条训练样本</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">gen_input_output</span>():
n = random.randint(<span class="hljs-number">1</span>, <span class="hljs-number">3</span>) <span class="hljs-comment"># 1~3组关系</span>
chosen = random.sample(relations, n)
chosen_chars = random.sample(characters, n * <span class="hljs-number">2</span>)
input_sentences = []
output_lines = []
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> <span class="hljs-built_in">range</span>(n):
c1 = chosen_chars[<span class="hljs-number">2</span> * i]
c2 = chosen_chars[<span class="hljs-number">2</span> * i + <span class="hljs-number">1</span>]
rel = chosen[i]
input_sentences.append(gen_sentence(c1, c2, rel))
output_lines.append(<span class="hljs-string">f"<span class="hljs-subst">{c1}</span>-<span class="hljs-subst">{c2}</span>:<span class="hljs-subst">{rel}</span>"</span>)
<span class="hljs-comment"># 构造 instruction 和 output</span>
instruction = <span class="hljs-string">"从以下小说内容中提取人物关系:"</span> + <span class="hljs-string">" "</span>.join(input_sentences)
<span class="hljs-keyword">return</span> {
<span class="hljs-string">"instruction"</span>: instruction,
<span class="hljs-string">"input"</span>: <span class="hljs-string">""</span>,
<span class="hljs-string">"output"</span>: <span class="hljs-string">"\n"</span>.join(output_lines)
}
<span class="hljs-comment"># 生成数据集</span>
data = [gen_input_output() <span class="hljs-keyword">for</span> _ <span class="hljs-keyword">in</span> <span class="hljs-built_in">range</span>(<span class="hljs-number">100</span>)]
<span class="hljs-comment"># 保存为 JSON 文件</span>
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(<span class="hljs-string">"rel.json"</span>, <span class="hljs-string">"w"</span>, encoding=<span class="hljs-string">"utf-8"</span>) <span class="hljs-keyword">as</span> f:
json.dump(data, f, ensure_ascii=<span class="hljs-literal">False</span>, indent=<span class="hljs-number">2</span>)
<span class="hljs-built_in">print</span>(<span class="hljs-string">"✅ 已生成1000条小说人物关系训练数据,保存在 rel_1000.json"</span>)
</code></div></pre>
<pre><div class="hljs"><code class="lang-json"><span class="hljs-punctuation">[</span>
<span class="hljs-punctuation">{</span>
<span class="hljs-attr">"instruction"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"从以下小说内容中提取人物关系:柳如烟是凤九的情敌。 江尘一直深爱着林清,两人是师尊。 东皇太一和沈墨曾是徒弟。"</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"input"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">""</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"output"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"柳如烟-凤九:情敌\n林清-江尘:师尊\n东皇太一-沈墨:徒弟"</span>
<span class="hljs-punctuation">}</span><span class="hljs-punctuation">,</span>
<span class="hljs-punctuation">{</span>
<span class="hljs-attr">"instruction"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"从以下小说内容中提取人物关系:楚风一直深爱着凤九,两人是师伯。 莫倾城与柳如烟是母子关系。"</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"input"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">""</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"output"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"凤九-楚风:师伯\n莫倾城-柳如烟:母子"</span>
<span class="hljs-punctuation">}</span><span class="hljs-punctuation">,</span>
<span class="hljs-punctuation">{</span>
<span class="hljs-attr">"instruction"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"从以下小说内容中提取人物关系:李慕白一直深爱着莫倾城,两人是战友。 东皇太一与柳如烟情同手足,是父子。"</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"input"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">""</span><span class="hljs-punctuation">,</span>
<span class="hljs-attr">"output"</span><span class="hljs-punctuation">:</span> <span class="hljs-string">"莫倾城-李慕白:战友\n东皇太一-柳如烟:父子"</span>
<span class="hljs-punctuation">}</span>
...
<span class="hljs-punctuation">]</span>
</code></div></pre>
<h2><a id="2__155"></a>2 训练代码</h2>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># VIP会员可见</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/5dc12b85f75d630547b662b5e2f43fcb.png" alt="image.png" /></p>
<h2><a id="3__163"></a>3 调用模型</h2>
<h3><a id="31__165"></a>3.1 单次调用</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># VIP可见</span>
</code></div></pre>
<h3><a id="32__171"></a>3.2 流式调用</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># VIP可见</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e385984f37e0e926b05e6abf8d4f5ef8.png" alt="image.png" /></p>

评论区