sentence-transformers文本向量化|语义搜索|相似度计算
有勇气的牛排
966
AI大模型
2025-07-21 21:07:07
1 前言
1.1 什么是 sentence-transformers
sentence-transformers 是一个基于BERT和其变种模型的Python库,用于生成高质量句子向量(sentence embeddings)。这些向量可以用于以下场景:
- 文本相似度计算
- 语义搜索(Semantic Search)
- 文本聚类
- 多轮问答
- 向量数据库索引(如FAISS、Milvus)
1.2 环境安装
python3.10
sentence-transformers==4.1.0
2 编码句子
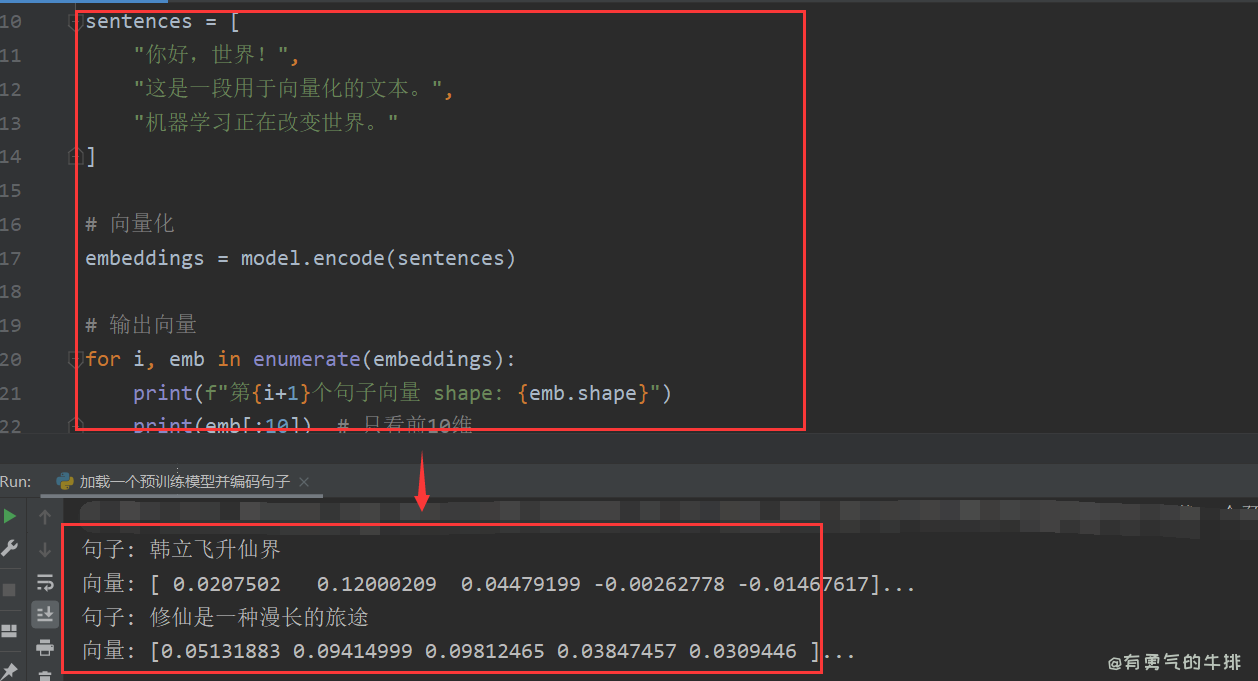
加载一个预训练模型并编码句子。
from sentence_transformers import SentenceTransformer
model_path = "./tmp/model/all-MiniLM-L6-v2"
model = SentenceTransformer(model_path)
sentences = ["韩立飞升仙界", "修仙是一种漫长的旅途"]
embeddings = model.encode(sentences)
for sentence, embedding in zip(sentences, embeddings):
print(f"句子: {sentence}")
print(f"向量: {embedding[:5]}...")
3 相似度计算
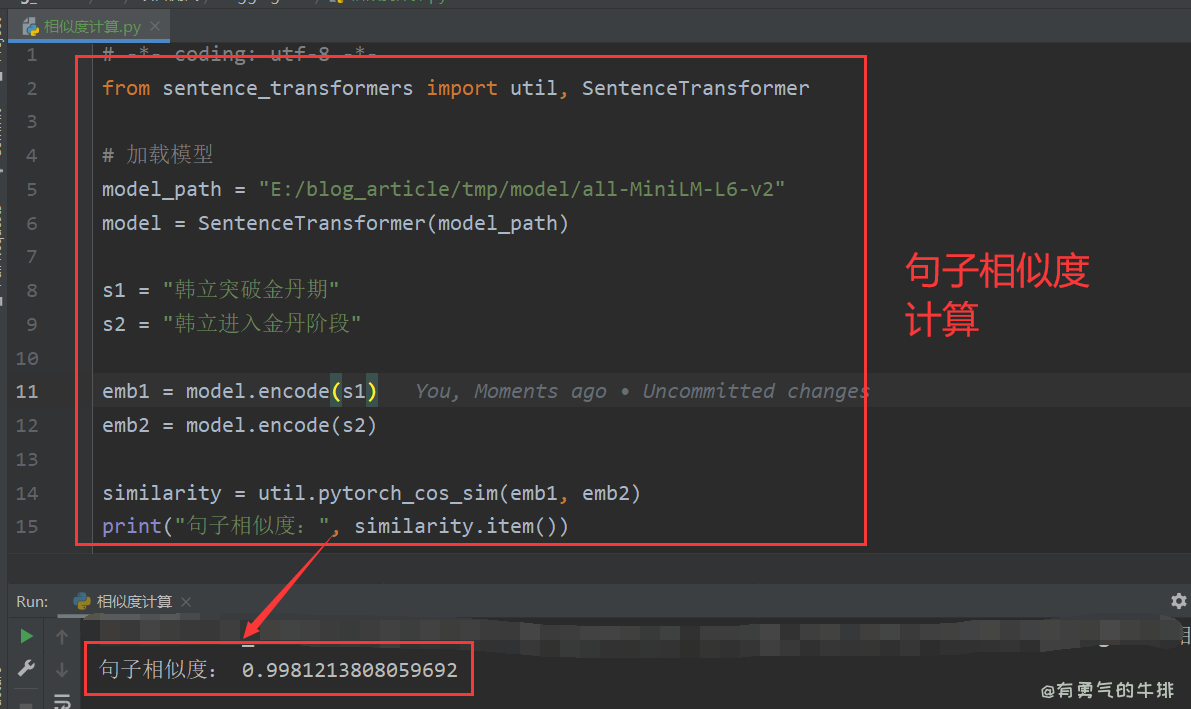
from sentence_transformers import util, SentenceTransformer
model_path = "./tmp/model/all-MiniLM-L6-v2"
model = SentenceTransformer(model_path)
s1 = "韩立突破金丹期"
s2 = "韩立进入金丹阶段"
emb1 = model.encode(s1)
emb2 = model.encode(s2)
similarity = util.pytorch_cos_sim(emb1, emb2)
print("句子相似度:", similarity.item())
4 语义搜索
from sentence_transformers import util,SentenceTransformer
model_path = "E:/blog_article/tmp/model/all-MiniLM-L6-v2"
model = SentenceTransformer(model_path)
corpus = [
"韩立突破金丹期",
"韩立在黑风山修炼",
"韩立炼制了丹药",
"王林在苍茫星修炼",
]
corpus_embedding = model.encode(corpus)
query = "韩立结丹"
query_embedding = model.encode(query)
hits = util.semantic_search(query_embedding, corpus_embedding, top_k=3)
for hit in hits[0]:
print(f"得分: {hit['score']:.4f}, 语句: {corpus[hit['corpus_id']]}")

5 与 FAISS 搭配构建向量检索系统
faiss-cpu
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
model_path = "E:/blog_article/tmp/model/all-MiniLM-L6-v2"
model = SentenceTransformer(model_path)
corpus = ["修仙者", "炼丹炉", "灵根测试", "灵石交易"]
corpus_embeddings = model.encode(corpus)
corpus_embeddings = np.array(corpus_embeddings).astype("float32")
index = faiss.IndexFlatL2(corpus_embeddings.shape[1])
index.add(corpus_embeddings)
query = "灵石购买"
query_embedding = model.encode([query]).astype("float32")
top_k = 2
distances, indices = index.search(query_embedding, top_k)
for idx, distance in zip(indices[0], distances[0]):
print(f"距离: {distance:.4f}, 匹配: {corpus[idx]}")

<h2><a id="1__0"></a>1 前言</h2>
<h3><a id="11__sentencetransformers_2"></a>1.1 什么是 sentence-transformers</h3>
<p><code>sentence-transformers</code> 是一个基于BERT和其变种模型的Python库,用于生成高质量句子向量(sentence embeddings)。这些向量可以用于以下场景:</p>
<ul>
<li>文本相似度计算</li>
<li>语义搜索(Semantic Search)</li>
<li>文本聚类</li>
<li>多轮问答</li>
<li>向量数据库索引(如FAISS、Milvus)</li>
</ul>
<h3><a id="12__12"></a>1.2 环境安装</h3>
<p>python3.10</p>
<pre><div class="hljs"><code class="lang-shell">sentence-transformers==4.1.0
</code></div></pre>
<h2><a id="2__20"></a>2 编码句子</h2>
<p>加载一个预训练模型并编码句子。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> SentenceTransformer
model_path = <span class="hljs-string">"./tmp/model/all-MiniLM-L6-v2"</span>
<span class="hljs-comment"># 加载模型</span>
model = SentenceTransformer(model_path)
<span class="hljs-comment"># 编码句子为向量</span>
sentences = [<span class="hljs-string">"韩立飞升仙界"</span>, <span class="hljs-string">"修仙是一种漫长的旅途"</span>]
embeddings = model.encode(sentences)
<span class="hljs-keyword">for</span> sentence, embedding <span class="hljs-keyword">in</span> <span class="hljs-built_in">zip</span>(sentences, embeddings):
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"句子: <span class="hljs-subst">{sentence}</span>"</span>)
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"向量: <span class="hljs-subst">{embedding[:<span class="hljs-number">5</span>]}</span>..."</span>) <span class="hljs-comment"># 仅展示前5维</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/19a22a1c72bca27c7cc1bccb9723461d.png" alt="sentence-transformers加载一个预训练模型并编码句子|文本向量化" /></p>
<h2><a id="3__44"></a>3 相似度计算</h2>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> util, SentenceTransformer
<span class="hljs-comment"># 加载模型</span>
model_path = <span class="hljs-string">"./tmp/model/all-MiniLM-L6-v2"</span>
model = SentenceTransformer(model_path)
s1 = <span class="hljs-string">"韩立突破金丹期"</span>
s2 = <span class="hljs-string">"韩立进入金丹阶段"</span>
emb1 = model.encode(s1)
emb2 = model.encode(s2)
similarity = util.pytorch_cos_sim(emb1, emb2)
<span class="hljs-built_in">print</span>(<span class="hljs-string">"句子相似度:"</span>, similarity.item())
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/f0e8bc576f71151e82a8a697f75ea37f.png" alt="sentence-transformers相似度计算" /></p>
<h2><a id="4__66"></a>4 语义搜索</h2>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> util,SentenceTransformer
<span class="hljs-comment"># 加载模型</span>
model_path = <span class="hljs-string">"E:/blog_article/tmp/model/all-MiniLM-L6-v2"</span>
model = SentenceTransformer(model_path)
<span class="hljs-comment"># 构建语料库</span>
corpus = [
<span class="hljs-string">"韩立突破金丹期"</span>,
<span class="hljs-string">"韩立在黑风山修炼"</span>,
<span class="hljs-string">"韩立炼制了丹药"</span>,
<span class="hljs-string">"王林在苍茫星修炼"</span>,
]
corpus_embedding = model.encode(corpus)
<span class="hljs-comment"># 查询句子</span>
query = <span class="hljs-string">"韩立结丹"</span>
query_embedding = model.encode(query)
<span class="hljs-comment"># 计算相似度得分</span>
hits = util.semantic_search(query_embedding, corpus_embedding, top_k=<span class="hljs-number">3</span>)
<span class="hljs-keyword">for</span> hit <span class="hljs-keyword">in</span> hits[<span class="hljs-number">0</span>]:
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"得分: <span class="hljs-subst">{hit[<span class="hljs-string">'score'</span>]:<span class="hljs-number">.4</span>f}</span>, 语句: <span class="hljs-subst">{corpus[hit[<span class="hljs-string">'corpus_id'</span>]]}</span>"</span>)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/4df48f2e4363042289c32b74293ce5fe.png" alt="sentence-transformers语义搜索" /></p>
<h2><a id="5__FAISS__99"></a>5 与 FAISS 搭配构建向量检索系统</h2>
<pre><div class="hljs"><code class="lang-shell">faiss-cpu
</code></div></pre>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">import</span> faiss
<span class="hljs-keyword">import</span> numpy <span class="hljs-keyword">as</span> np
<span class="hljs-keyword">from</span> sentence_transformers <span class="hljs-keyword">import</span> SentenceTransformer
<span class="hljs-comment"># 加载模型</span>
model_path = <span class="hljs-string">"E:/blog_article/tmp/model/all-MiniLM-L6-v2"</span>
model = SentenceTransformer(model_path)
<span class="hljs-comment"># 构建语料</span>
corpus = [<span class="hljs-string">"修仙者"</span>, <span class="hljs-string">"炼丹炉"</span>, <span class="hljs-string">"灵根测试"</span>, <span class="hljs-string">"灵石交易"</span>]
corpus_embeddings = model.encode(corpus)
<span class="hljs-comment"># 转换为 float32</span>
corpus_embeddings = np.array(corpus_embeddings).astype(<span class="hljs-string">"float32"</span>)
<span class="hljs-comment"># 创建 FAISS 索引</span>
index = faiss.IndexFlatL2(corpus_embeddings.shape[<span class="hljs-number">1</span>])
index.add(corpus_embeddings)
<span class="hljs-comment"># 查询向量</span>
query = <span class="hljs-string">"灵石购买"</span>
query_embedding = model.encode([query]).astype(<span class="hljs-string">"float32"</span>)
<span class="hljs-comment"># 搜索</span>
top_k = <span class="hljs-number">2</span>
distances, indices = index.search(query_embedding, top_k)
<span class="hljs-keyword">for</span> idx, distance <span class="hljs-keyword">in</span> <span class="hljs-built_in">zip</span>(indices[<span class="hljs-number">0</span>], distances[<span class="hljs-number">0</span>]):
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"距离: <span class="hljs-subst">{distance:<span class="hljs-number">.4</span>f}</span>, 匹配: <span class="hljs-subst">{corpus[idx]}</span>"</span>)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/3b7f35c0cbb58f7ce84af10a54a258f3.png" alt="sentence-transformers与 FAISS 搭配构建向量检索系统" /></p>

评论区