1 前言
1.1 定义
在 LangChain 中,文档加载器(Document Loaders) 用于将各种文件格式(如 txt、PDF 等)读取并转换为统一的数据结构 Document,便于后续进行向量化、问答、摘要等操作。
1.2 Document 对象结构说明
LangChain 中加载的每一份文档都会被转换为一个或多个 Document 对象,其结构如下:
Document(
page_content="文档的主要文本内容",
metadata={"source": "文件路径", "page": 页码(如果有)}
)
page_content:文档主体内容(字符串)metadata:文档元数据,如文件名、页码、来源路径等
1.3 环境安装
python3.10
langchain-community==0.3.27
3 场景案例
3.1 加载 TXT 文本文件
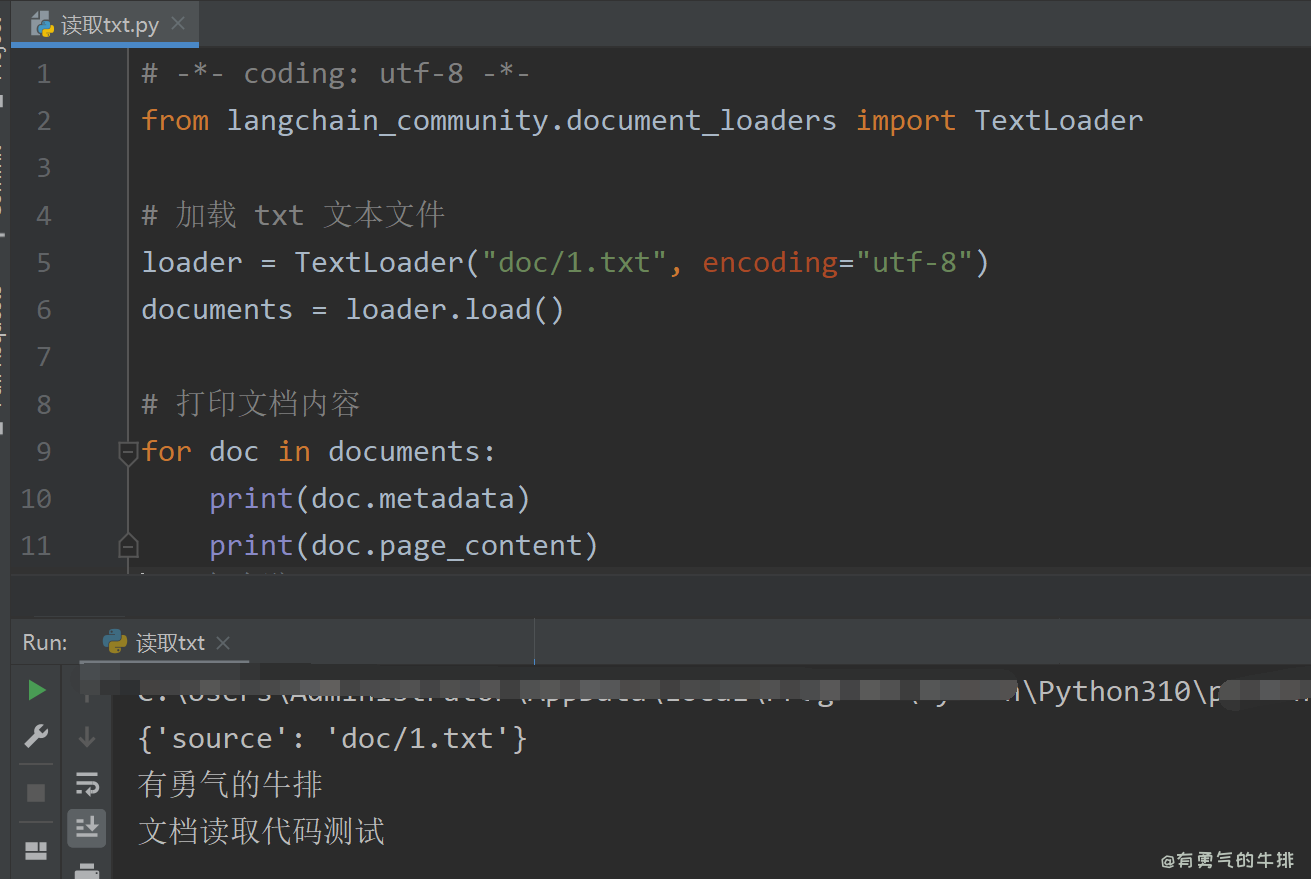
使用 TextLoader 加载纯文本文件
from langchain_community.document_loaders import TextLoader
loader = TextLoader("doc/1.txt", encoding="utf-8")
documents = loader.load()
for doc in documents:
print(doc.metadata)
print(doc.page_content)
3.2 加载 PDF 文件
使用 PyPDFLoader 加载 PDF 文件
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("doc/红楼梦.pdf")
pages = loader.load_and_split()
for i, page in enumerate(pages[:5]):
print(f"第 {i+1} 页内容:")
print(page.page_content[:300])
print("-" * 60)
说明:
load_and_split() 会将 PDF 拆分为按页组织的多个 Document- 每页成为一个独立
Document,保留页码信息 metadata['page']
- 特别适合后续 向量化检索 或 逐页问答分析
3.3 加载word
pip install "unstructured[all-docs]"
unstructured==0.18.9
python-docx==1.2.0
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 加载 Word 文档(.docx)
loader = UnstructuredWordDocumentLoader("doc/cs.docx")
documents = loader.load()
# 打印内容
for doc in documents:
print(doc.metadata)
print(doc.page_content[:300]) # 输出前300字符
支持ORC
pip install "unstructured[all-docs,local-inference]" pytesseract pillow python-docx
unstructured==0.18.9
python-docx==1.2.0
3.4 加载 Markdown 文档
使用 UnstructuredMarkdownLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./LangChain教程.md")
documents = loader.load()
for doc in documents:
print(doc.metadata)
print(doc.page_content[:300])
4 应用场景
无论是 TXT 还是 PDF 加载后得到的 Document 对象,都可以用于以下 LangChain 应用:
- 🔍 向量数据库存储(如 FAISS)
- ❓ 基于文档的问答(Retrieval QA)
- 📝 文本摘要、翻译、分类等任务
- 🔄 多语言处理或批量预处理
5 其他
OCR项目
https://github.com/tesseract-ocr/tesseract
<h2><a id="1__0"></a>1 前言</h2>
<h3><a id="11__2"></a>1.1 定义</h3>
<p>在 LangChain 中,<strong>文档加载器(Document Loaders)</strong> 用于将各种文件格式(如 txt、PDF 等)读取并转换为统一的数据结构 <code>Document</code>,便于后续进行向量化、问答、摘要等操作。</p>
<h3><a id="12_Document__6"></a>1.2 Document 对象结构说明</h3>
<p>LangChain 中加载的每一份文档都会被转换为一个或多个 <code>Document</code> 对象,其结构如下:</p>
<pre><div class="hljs"><code class="lang-python">Document(
page_content=<span class="hljs-string">"文档的主要文本内容"</span>,
metadata={<span class="hljs-string">"source"</span>: <span class="hljs-string">"文件路径"</span>, <span class="hljs-string">"page"</span>: 页码(如果有)}
)
</code></div></pre>
<ul>
<li><code>page_content</code>:文档主体内容(字符串)</li>
<li><code>metadata</code>:文档元数据,如文件名、页码、来源路径等</li>
</ul>
<h3><a id="13__20"></a>1.3 环境安装</h3>
<p>python3.10</p>
<pre><div class="hljs"><code class="lang-shell">langchain-community==0.3.27
</code></div></pre>
<h2><a id="3__28"></a>3 场景案例</h2>
<h3><a id="31__TXT__30"></a>3.1 加载 TXT 文本文件</h3>
<p>使用 <code>TextLoader</code> 加载纯文本文件</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> langchain_community.document_loaders <span class="hljs-keyword">import</span> TextLoader
<span class="hljs-comment"># 1. 创建 TXT 加载器实例</span>
loader = TextLoader(<span class="hljs-string">"doc/1.txt"</span>, encoding=<span class="hljs-string">"utf-8"</span>)
<span class="hljs-comment"># 2. 加载文档,返回的是一个 Document 列表</span>
documents = loader.load()
<span class="hljs-comment"># 3. 遍历输出每个文档的内容和元信息</span>
<span class="hljs-keyword">for</span> doc <span class="hljs-keyword">in</span> documents:
<span class="hljs-built_in">print</span>(doc.metadata) <span class="hljs-comment"># 输出元数据,如文件路径</span>
<span class="hljs-built_in">print</span>(doc.page_content) <span class="hljs-comment"># 输出正文内容</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/b4829456e8de8c3472b04556479b6009.png" alt="LangChain 加载 TXT 文本文件" /></p>
<h3><a id="32__PDF__52"></a>3.2 加载 PDF 文件</h3>
<p>使用 <code>PyPDFLoader</code> 加载 PDF 文件</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain_community.document_loaders <span class="hljs-keyword">import</span> PyPDFLoader
<span class="hljs-comment"># 1. 创建 PDF 加载器实例</span>
loader = PyPDFLoader(<span class="hljs-string">"doc/红楼梦.pdf"</span>)
<span class="hljs-comment"># 2. 加载并自动按页拆分成多个 Document 实例</span>
pages = loader.load_and_split()
<span class="hljs-comment"># 3. 输出前5页内容预览</span>
<span class="hljs-keyword">for</span> i, page <span class="hljs-keyword">in</span> <span class="hljs-built_in">enumerate</span>(pages[:<span class="hljs-number">5</span>]):
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"第 <span class="hljs-subst">{i+<span class="hljs-number">1</span>}</span> 页内容:"</span>)
<span class="hljs-built_in">print</span>(page.page_content[:<span class="hljs-number">300</span>]) <span class="hljs-comment"># 每页仅显示前300字符</span>
<span class="hljs-built_in">print</span>(<span class="hljs-string">"-"</span> * <span class="hljs-number">60</span>)
</code></div></pre>
<p>说明:</p>
<ul>
<li><code>load_and_split()</code> 会将 PDF 拆分为按页组织的多个 <code>Document</code></li>
<li>每页成为一个独立 <code>Document</code>,保留页码信息 <code>metadata['page']</code></li>
<li>特别适合后续 <strong>向量化检索</strong> 或 <strong>逐页问答分析</strong></li>
</ul>
<h3><a id="33_word_78"></a>3.3 加载word</h3>
<pre><div class="hljs"><code class="lang-shell">pip install "unstructured[all-docs]"
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">unstructured==0.18.9
python-docx==1.2.0
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">from langchain_community.document_loaders import UnstructuredWordDocumentLoader
<span class="hljs-meta">
# </span><span class="language-bash">加载 Word 文档(.docx)</span>
loader = UnstructuredWordDocumentLoader("doc/cs.docx")
documents = loader.load()
<span class="hljs-meta">
# </span><span class="language-bash">打印内容</span>
for doc in documents:
print(doc.metadata)
print(doc.page_content[:300]) # 输出前300字符
</code></div></pre>
<p>支持ORC</p>
<pre><div class="hljs"><code class="lang-shell">pip install "unstructured[all-docs,local-inference]" pytesseract pillow python-docx
</code></div></pre>
<pre><div class="hljs"><code class="lang-shell">unstructured==0.18.9
python-docx==1.2.0
</code></div></pre>
<h3><a id="34___Markdown__115"></a>3.4 加载 Markdown 文档</h3>
<p>使用 <code>UnstructuredMarkdownLoader</code></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> langchain_community.document_loaders <span class="hljs-keyword">import</span> UnstructuredMarkdownLoader
<span class="hljs-comment"># 加载 Markdown 文件</span>
loader = UnstructuredMarkdownLoader(<span class="hljs-string">"./LangChain教程.md"</span>)
documents = loader.load()
<span class="hljs-comment"># 打印 Markdown 正文内容</span>
<span class="hljs-keyword">for</span> doc <span class="hljs-keyword">in</span> documents:
<span class="hljs-built_in">print</span>(doc.metadata)
<span class="hljs-built_in">print</span>(doc.page_content[:<span class="hljs-number">300</span>])
</code></div></pre>
<h2><a id="4__132"></a>4 应用场景</h2>
<p>无论是 TXT 还是 PDF 加载后得到的 <code>Document</code> 对象,都可以用于以下 LangChain 应用:</p>
<ul>
<li>🔍 <strong>向量数据库存储(如 FAISS)</strong></li>
<li>❓ <strong>基于文档的问答(Retrieval QA)</strong></li>
<li>📝 <strong>文本摘要、翻译、分类等任务</strong></li>
<li>🔄 <strong>多语言处理或批量预处理</strong></li>
</ul>
<h2><a id="5__143"></a>5 其他</h2>
<p>OCR项目</p>
<p><a href="https://github.com/tesseract-ocr/tesseract" target="_blank">https://github.com/tesseract-ocr/tesseract</a></p>

评论区