Pyppeteer爬虫教程:从入门到精通的全面指南
1 前言
Pyppeteer 是 Google 基于 Node.js 开发的工具,而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本实现。不过,Pyppeteer 并不是由 Google 开发的,而是一位日本工程师根据 Puppeteer 的功能开发出来的非官方版本。
在 Pyppeteer 中,它实际上在后台使用了 Chromium 浏览器来执行网页渲染操作。这两款浏览器(Chromium 和 Chrome)的内核是一样的,可以认为 Chromium 是开发版,而 Chrome 是正式版。
官方文档:https://miyakogi.github.io/pyppeteer/reference.html
2 环境安装
python3.8.5
pyppeteer==0.2.2
websockets==8.1
python3.10.9
pyppeteer==0.2.6
websockets==10.3
注意:需要支持异步,Python3.5+
3 基本参数
params = {
'headless': False,
'dumpio': True,
r'userDateDir': './cache-data',
'args': [
'--disable-infobars',
'--window-size=1920, 1080',
'--log-level=30',
'--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'--no-sandbox',
'--start-maximized',
'--proxy-server=http://127.0.0.1:7890'
]
}
4 案例
4.1 百度搜索
import asyncio
import time
from pyppeteer import launch
async def main():
url = "https://www.baidu.com/"
browser = await launch(**params)
page = await browser.newPage()
await page.setViewport({'width': 1900, 'height': 1080})
await page.goto(url)
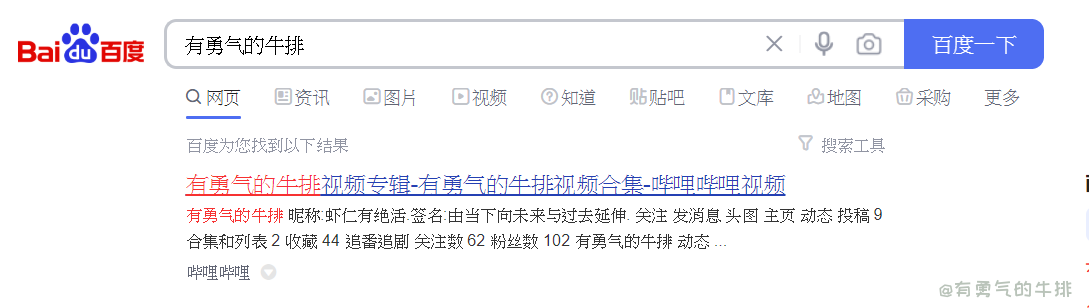
await page.type('#kw', '有勇气的牛排')
await page.click('#su')
time.sleep(5)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
4.2 xpath爬虫解析a标签
import asyncio
import time
from pyppeteer import launch
async def main():
url = "https://www.couragesteak.com/article/389"
browser = await launch(**params)
page = await browser.newPage()
await page.setViewport({'width': 1900, 'height': 1080})
await page.goto(url)
xpath = '/html/body/main/article/center[2]/div/a'
await page.waitForXPath(xpath)
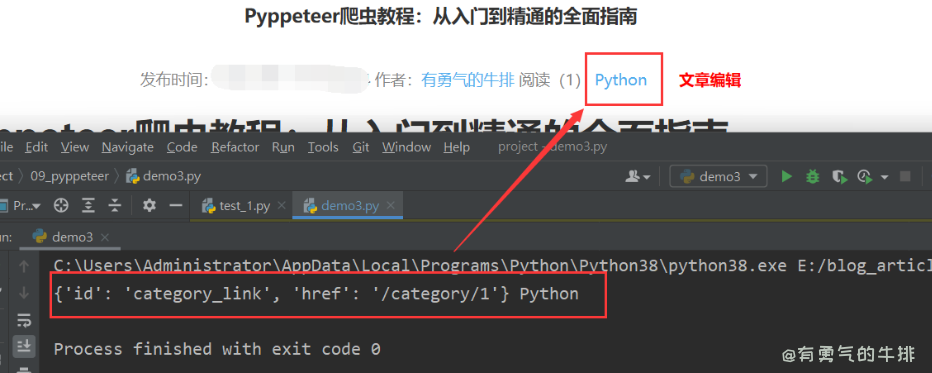
a_element = await page.xpath(xpath)
if a_element:
a_element = a_element[0]
attributes = await page.evaluate('(element) => {'
' const attrs = {};'
' for (let attr of element.attributes) {'
' attrs[attr.name] = attr.value;'
' }'
' return attrs;'
'}', a_element)
text_content = await page.evaluate('(element) => element.textContent', a_element)
print(attributes, text_content)
time.sleep(5)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
5 常用功能
Pyppeteer 三种解析方式
Page.querySelector()
Page.xpath()
Page.J(), Page.JJ(), and Page.Jx()
5.1 截屏
原创:有勇气的牛排
参考地址:https://www.couragesteak.com/article/453
await page.screenshot(path='my.png')
5.2 伪装浏览器 绕过检测
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象。
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator, { webdriver: { get: () => false } }) }')
验证查看
window.navigator.webdriver
5.3 执行js
my_cookie = await page.evaluate('''
() => {
return {
cookie: window.document.cookie
}
}
''')
print(my_cookie["cookie"])
5.4 滚动到页面底部
await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')
5.6 提取文本
element = await page.querySelector(f'.d_time')
text = await page.evaluate('(element) => element.textContent', element)
print(f"text: {text}")
5.7 批量提取指定元素/id/class的文本
这里以span标签为例
await page.waitForSelector('span')
li_elements = await page.querySelectorAll('span')
li_texts = [await page.evaluate('(element) => element.textContent', li) for li in li_elements]
print(li_texts)
for i in li_texts:
print(i)
5.8 提取超链接属性 a
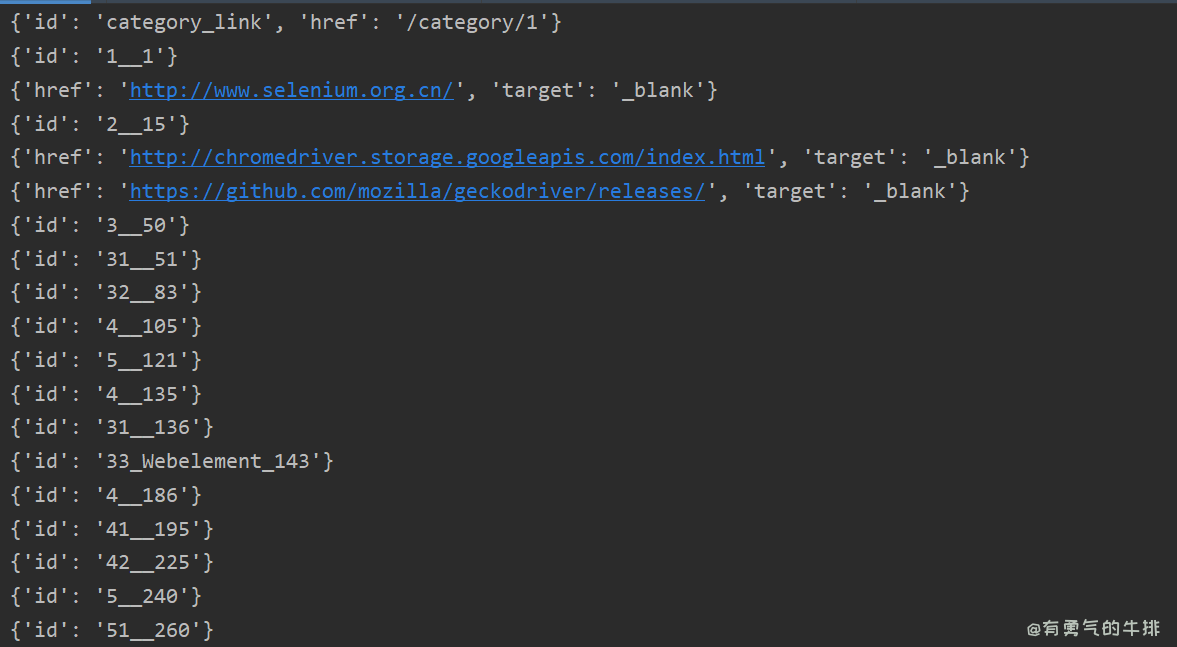
a_elements = await page.querySelectorAll('a')
a_attributes = []
for a in a_elements:
attributes = await page.evaluate('(element) => {'
' const attrs = {};'
' for (let attr of element.attributes) {'
' attrs[attr.name] = attr.value;'
' }'
' return attrs;'
'}', a)
a_attributes.append(attributes)
print(attributes)
5.9 XPath 获取属性内容 a标签
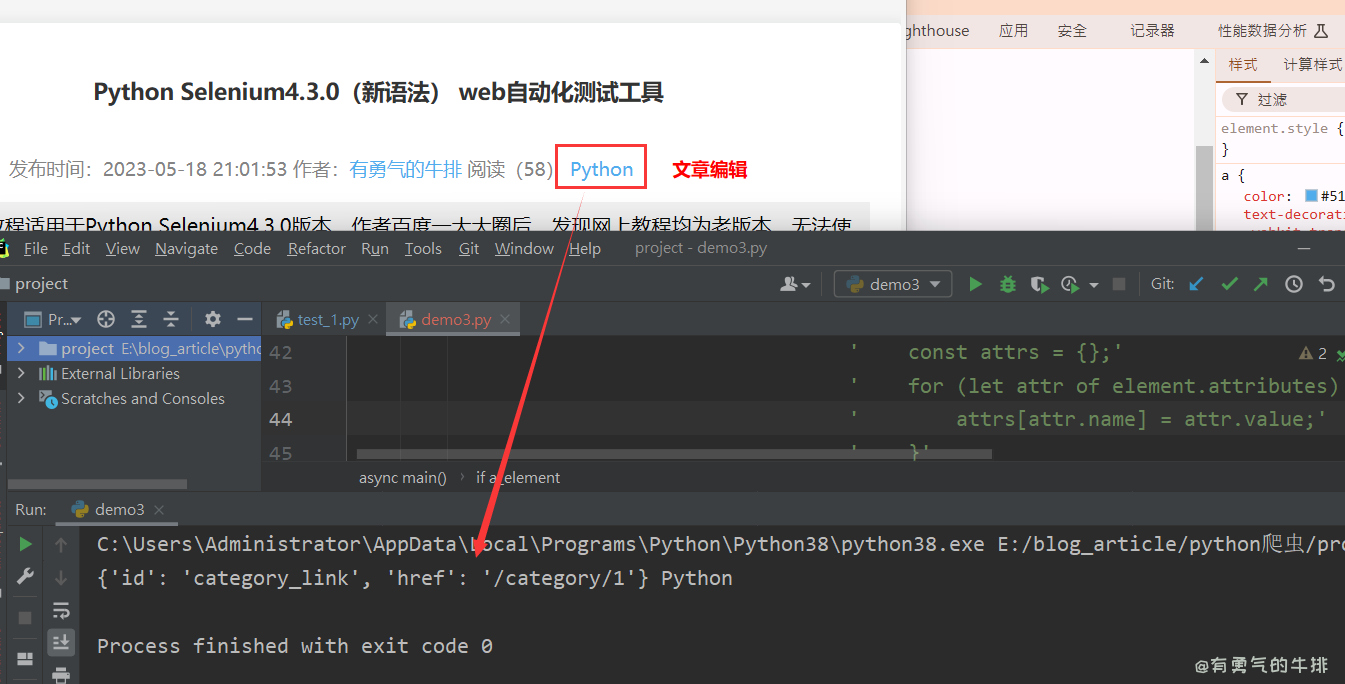
xpath = '/html/body/main/article/center[2]/div/a'
await page.waitForXPath(xpath)
a_element = await page.xpath(xpath)
if a_element:
a_element = a_element[0]
attributes = await page.evaluate('(element) => {'
' const attrs = {};'
' for (let attr of element.attributes) {'
' attrs[attr.name] = attr.value;'
' }'
' return attrs;'
'}', a_element)
text_content = await page.evaluate('(element) => element.textContent', a_element)
print(attributes, text_content)
5.10 获取cookie
cookies = await page.cookies()
print(cookies)
5.11 其他参数
ignoreHTTPSErrors(bool): 是否忽略 HTTPS 错误。默认为 False.
headless(bool): 是否以无头模式运行浏览器。默认为 True除非appMode或devtools选项是True。
executablePath(str):要运行的 Chromium 或 Chrome 可执行文件的路径,而不是默认捆绑的 Chromium。
slowMo(int|float):将 pyppeteer 操作减慢指定的毫秒数。
args(List[str]):传递给浏览器进程的附加参数(标志)。
ignoreDefaultArgs(bool): 不要使用 pyppeteer 的默认参数。这是一个危险的选择;小心使用。
handleSIGINT(bool):按 Ctrl+C 关闭浏览器进程。默认为 True.
handleSIGTERM(bool):在 SIGTERM 时关闭浏览器进程。默认为True.
handleSIGHUP(bool):在 SIGHUP 上关闭浏览器进程。默认为 True.
dumpio(bool): 是否将浏览器进程 stdout 和 stderr 通过管道传输到process.stdout和process.stderr。默认为False.
userDataDir(str):用户数据目录的路径。
env(dict):指定浏览器可见的环境变量。默认与 python 进程相同。
devtools(bool):是否为每个选项卡自动打开 DevTools 面板。如果有此选项True,则该headless选项将被设置 False。
logLevel(int|str):打印日志的日志级别。默认与根记录器相同。
autoClose(bool):脚本完成后自动关闭浏览器进程。默认为True.
loop(asyncio.AbstractEventLoop):事件循环(实验性)。
appMode(bool):已弃用。
6 提取数据
await page.waitForXPath('//*[@id="page"]')
print(await page.content())
J = querySelector
Jeval = querySelectorEval
JJ = querySelectorAll
JJeval = querySelectorEval
Jx = xpath
<h1><a id="Pyppeteer_0"></a>Pyppeteer爬虫教程:从入门到精通的全面指南</h1>
<h2><a id="1__2"></a>1 前言</h2>
<p>Pyppeteer 是 Google 基于 Node.js 开发的工具,而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本实现。不过,Pyppeteer 并不是由 Google 开发的,而是一位日本工程师根据 Puppeteer 的功能开发出来的非官方版本。</p>
<p>在 Pyppeteer 中,它实际上在后台使用了 Chromium 浏览器来执行网页渲染操作。这两款浏览器(Chromium 和 Chrome)的内核是一样的,可以认为 Chromium 是开发版,而 Chrome 是正式版。</p>
<p>官方文档:<a href="https://miyakogi.github.io/pyppeteer/reference.html" target="_blank">https://miyakogi.github.io/pyppeteer/reference.html</a></p>
<h2><a id="2__14"></a>2 环境安装</h2>
<p>python3.8.5</p>
<pre><div class="hljs"><code class="lang-shell">pyppeteer==0.2.2
websockets==8.1
</code></div></pre>
<p>python3.10.9</p>
<pre><div class="hljs"><code class="lang-shell">pyppeteer==0.2.6
websockets==10.3
</code></div></pre>
<p>注意:需要支持异步,Python3.5+</p>
<h2><a id="3__31"></a>3 基本参数</h2>
<pre><div class="hljs"><code class="lang-python">params = {
<span class="hljs-string">'headless'</span>: <span class="hljs-literal">False</span>, <span class="hljs-comment"># 关闭无头浏览器</span>
<span class="hljs-string">'dumpio'</span>: <span class="hljs-literal">True</span>, <span class="hljs-comment"># 防止浏览器卡主</span>
<span class="hljs-string">r'userDateDir'</span>: <span class="hljs-string">'./cache-data'</span>, <span class="hljs-comment"># 用户文件地址</span>
<span class="hljs-string">'args'</span>: [
<span class="hljs-string">'--disable-infobars'</span>, <span class="hljs-comment"># 关闭 自动化提示框</span>
<span class="hljs-string">'--window-size=1920, 1080'</span>, <span class="hljs-comment"># 窗口大小</span>
<span class="hljs-string">'--log-level=30'</span>, <span class="hljs-comment"># 日志保存等级,建议设置越小越好,否则生成的日志占用空间很大 30为 warning级别</span>
<span class="hljs-string">'--user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'</span>,
<span class="hljs-string">'--no-sandbox'</span>, <span class="hljs-comment"># 关闭 沙盒模式</span>
<span class="hljs-string">'--start-maximized'</span>, <span class="hljs-comment"># 窗口 最大化 模式</span>
<span class="hljs-string">'--proxy-server=http://127.0.0.1:7890'</span> <span class="hljs-comment"># 代理</span>
]
}
</code></div></pre>
<h2><a id="4__52"></a>4 案例</h2>
<h3><a id="41__54"></a>4.1 百度搜索</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> asyncio
<span class="hljs-keyword">import</span> time
<span class="hljs-keyword">from</span> pyppeteer <span class="hljs-keyword">import</span> launch
<span class="hljs-keyword">async</span> <span class="hljs-keyword">def</span> <span class="hljs-title function_">main</span>():
url = <span class="hljs-string">"https://www.baidu.com/"</span>
<span class="hljs-comment"># 启动一个浏览器</span>
<span class="hljs-comment"># browser = await launch(headless=False, args=['--disable-infobars', '--window-size=1920, 1080'])</span>
browser = <span class="hljs-keyword">await</span> launch(**params)
<span class="hljs-comment"># 创建一个页面</span>
page = <span class="hljs-keyword">await</span> browser.newPage()
<span class="hljs-comment"># 设置页面视图大小</span>
<span class="hljs-keyword">await</span> page.setViewport({<span class="hljs-string">'width'</span>: <span class="hljs-number">1900</span>, <span class="hljs-string">'height'</span>: <span class="hljs-number">1080</span>})
<span class="hljs-comment"># 跳转到百度</span>
<span class="hljs-keyword">await</span> page.goto(url)
<span class="hljs-comment"># 输入要查询的关键字 (select, 内容)</span>
<span class="hljs-keyword">await</span> page.<span class="hljs-built_in">type</span>(<span class="hljs-string">'#kw'</span>, <span class="hljs-string">'有勇气的牛排'</span>)
<span class="hljs-comment"># 点击提交按钮 click 通过 selector点击指定的元素</span>
<span class="hljs-keyword">await</span> page.click(<span class="hljs-string">'#su'</span>)
time.sleep(<span class="hljs-number">5</span>)
<span class="hljs-keyword">await</span> browser.close()
asyncio.get_event_loop().run_until_complete(main())
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/0454f06ce98bafee13d0d9e4f379f051.png" alt="image.png" /></p>
<h3><a id="42_xpatha_86"></a>4.2 xpath爬虫解析a标签</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> asyncio
<span class="hljs-keyword">import</span> time
<span class="hljs-keyword">from</span> pyppeteer <span class="hljs-keyword">import</span> launch
<span class="hljs-keyword">async</span> <span class="hljs-keyword">def</span> <span class="hljs-title function_">main</span>():
url = <span class="hljs-string">"https://www.couragesteak.com/article/389"</span>
<span class="hljs-comment"># 启动一个浏览器</span>
browser = <span class="hljs-keyword">await</span> launch(**params)
<span class="hljs-comment"># 创建一个页面</span>
page = <span class="hljs-keyword">await</span> browser.newPage()
<span class="hljs-comment"># 设置页面视图大小</span>
<span class="hljs-keyword">await</span> page.setViewport({<span class="hljs-string">'width'</span>: <span class="hljs-number">1900</span>, <span class="hljs-string">'height'</span>: <span class="hljs-number">1080</span>})
<span class="hljs-comment"># 跳转到页面</span>
<span class="hljs-keyword">await</span> page.goto(url)
<span class="hljs-comment"># 使用XPath选择指定的a元素</span>
xpath = <span class="hljs-string">'/html/body/main/article/center[2]/div/a'</span>
<span class="hljs-keyword">await</span> page.waitForXPath(xpath)
a_element = <span class="hljs-keyword">await</span> page.xpath(xpath)
<span class="hljs-keyword">if</span> a_element:
a_element = a_element[<span class="hljs-number">0</span>] <span class="hljs-comment"># 选择第一个匹配的元素</span>
<span class="hljs-comment"># 提取属性</span>
attributes = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => {'</span>
<span class="hljs-string">' const attrs = {};'</span>
<span class="hljs-string">' for (let attr of element.attributes) {'</span>
<span class="hljs-string">' attrs[attr.name] = attr.value;'</span>
<span class="hljs-string">' }'</span>
<span class="hljs-string">' return attrs;'</span>
<span class="hljs-string">'}'</span>, a_element)
<span class="hljs-comment"># 提取文本内容</span>
text_content = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => element.textContent'</span>, a_element)
<span class="hljs-built_in">print</span>(attributes, text_content)
time.sleep(<span class="hljs-number">5</span>)
<span class="hljs-keyword">await</span> browser.close()
asyncio.get_event_loop().run_until_complete(main())
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/3b800bd4e1678ac991efd1e7a5ea8c05.png" alt="Xpath提取a标签内容属性" /></p>
<h2><a id="5__134"></a>5 常用功能</h2>
<p>Pyppeteer 三种解析方式</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># CSS选择器</span>
Page.querySelector()
<span class="hljs-comment"># xpath表达式</span>
Page.xpath()
<span class="hljs-comment"># 简写</span>
Page.J(), Page.JJ(), <span class="hljs-keyword">and</span> Page.Jx()
</code></div></pre>
<h3><a id="51__151"></a>5.1 截屏</h3>
<p>原创:有勇气的牛排<br />
参考地址:<a href="https://www.couragesteak.com/article/453" target="_blank">https://www.couragesteak.com/article/453</a></p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 截屏</span>
<span class="hljs-keyword">await</span> page.screenshot(path=<span class="hljs-string">'my.png'</span>)
</code></div></pre>
<h3><a id="52___163"></a>5.2 伪装浏览器 绕过检测</h3>
<p>Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 伪装浏览器 绕过检测</span>
<span class="hljs-keyword">await</span> page.evaluateOnNewDocument(<span class="hljs-string">'() =>{ Object.defineProperties(navigator, { webdriver: { get: () => false } }) }'</span>)
</code></div></pre>
<p>验证查看</p>
<pre><div class="hljs"><code class="lang-js"><span class="hljs-variable language_">window</span>.<span class="hljs-property">navigator</span>.<span class="hljs-property">webdriver</span>
</code></div></pre>
<h3><a id="53_js_180"></a>5.3 执行js</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 执行js (这里是es6的箭头函数)</span>
my_cookie = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'''
() => {
return {
cookie: window.document.cookie
}
}
'''</span>)
<span class="hljs-built_in">print</span>(my_cookie[<span class="hljs-string">"cookie"</span>])
</code></div></pre>
<h3><a id="54__196"></a>5.4 滚动到页面底部</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 滚到到页面底部</span>
<span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'window.scrollBy(0, document.body.scrollHeight)'</span>)
</code></div></pre>
<h3><a id="56__203"></a>5.6 提取文本</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 提取元素中的文本</span>
element = <span class="hljs-keyword">await</span> page.querySelector(<span class="hljs-string">f'.d_time'</span>)
text = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => element.textContent'</span>, element)
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"text: <span class="hljs-subst">{text}</span>"</span>)
</code></div></pre>
<h3><a id="57_idclass_212"></a>5.7 批量提取指定元素/id/class的文本</h3>
<p>这里以span标签为例</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 等待所有li元素加载</span>
<span class="hljs-keyword">await</span> page.waitForSelector(<span class="hljs-string">'span'</span>)
<span class="hljs-comment"># 提取所有li元素中的文本</span>
li_elements = <span class="hljs-keyword">await</span> page.querySelectorAll(<span class="hljs-string">'span'</span>)
li_texts = [<span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => element.textContent'</span>, li) <span class="hljs-keyword">for</span> li <span class="hljs-keyword">in</span> li_elements]
<span class="hljs-built_in">print</span>(li_texts)
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> li_texts:
<span class="hljs-built_in">print</span>(i)
</code></div></pre>
<h3><a id="58__a_227"></a>5.8 提取超链接属性 a</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 提取所有a元素及其属性</span>
a_elements = <span class="hljs-keyword">await</span> page.querySelectorAll(<span class="hljs-string">'a'</span>)
a_attributes = []
<span class="hljs-keyword">for</span> a <span class="hljs-keyword">in</span> a_elements:
attributes = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => {'</span>
<span class="hljs-string">' const attrs = {};'</span>
<span class="hljs-string">' for (let attr of element.attributes) {'</span>
<span class="hljs-string">' attrs[attr.name] = attr.value;'</span>
<span class="hljs-string">' }'</span>
<span class="hljs-string">' return attrs;'</span>
<span class="hljs-string">'}'</span>, a)
a_attributes.append(attributes)
<span class="hljs-built_in">print</span>(attributes)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/d7c0bed89b0961b8ea23ee51762404de.png" alt="image.png" /></p>
<h3><a id="59_XPath__a_247"></a>5.9 XPath 获取属性内容 a标签</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 使用XPath选择指定的a元素</span>
xpath = <span class="hljs-string">'/html/body/main/article/center[2]/div/a'</span>
<span class="hljs-keyword">await</span> page.waitForXPath(xpath)
a_element = <span class="hljs-keyword">await</span> page.xpath(xpath)
<span class="hljs-keyword">if</span> a_element:
a_element = a_element[<span class="hljs-number">0</span>] <span class="hljs-comment"># 选择第一个匹配的元素</span>
<span class="hljs-comment"># 提取属性</span>
attributes = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => {'</span>
<span class="hljs-string">' const attrs = {};'</span>
<span class="hljs-string">' for (let attr of element.attributes) {'</span>
<span class="hljs-string">' attrs[attr.name] = attr.value;'</span>
<span class="hljs-string">' }'</span>
<span class="hljs-string">' return attrs;'</span>
<span class="hljs-string">'}'</span>, a_element)
<span class="hljs-comment"># 提取文本内容</span>
text_content = <span class="hljs-keyword">await</span> page.evaluate(<span class="hljs-string">'(element) => element.textContent'</span>, a_element)
<span class="hljs-built_in">print</span>(attributes, text_content)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/eb487ac5ec58008d85183678aefbaed8.png" alt="image.png" /></p>
<h3><a id="510_cookie_273"></a>5.10 获取cookie</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 获取Cookie</span>
cookies = <span class="hljs-keyword">await</span> page.cookies()
<span class="hljs-built_in">print</span>(cookies)
</code></div></pre>
<h3><a id="511__284"></a>5.11 其他参数</h3>
<pre><div class="hljs"><code class="lang-shell">ignoreHTTPSErrors(bool): 是否忽略 HTTPS 错误。默认为 False.
headless(bool): 是否以无头模式运行浏览器。默认为 True除非appMode或devtools选项是True。
executablePath(str):要运行的 Chromium 或 Chrome 可执行文件的路径,而不是默认捆绑的 Chromium。
slowMo(int|float):将 pyppeteer 操作减慢指定的毫秒数。
args(List[str]):传递给浏览器进程的附加参数(标志)。
ignoreDefaultArgs(bool): 不要使用 pyppeteer 的默认参数。这是一个危险的选择;小心使用。
handleSIGINT(bool):按 Ctrl+C 关闭浏览器进程。默认为 True.
handleSIGTERM(bool):在 SIGTERM 时关闭浏览器进程。默认为True.
handleSIGHUP(bool):在 SIGHUP 上关闭浏览器进程。默认为 True.
dumpio(bool): 是否将浏览器进程 stdout 和 stderr 通过管道传输到process.stdout和process.stderr。默认为False.
userDataDir(str):用户数据目录的路径。
env(dict):指定浏览器可见的环境变量。默认与 python 进程相同。
devtools(bool):是否为每个选项卡自动打开 DevTools 面板。如果有此选项True,则该headless选项将被设置 False。
logLevel(int|str):打印日志的日志级别。默认与根记录器相同。
autoClose(bool):脚本完成后自动关闭浏览器进程。默认为True.
loop(asyncio.AbstractEventLoop):事件循环(实验性)。
appMode(bool):已弃用。
</code></div></pre>
<h2><a id="6__306"></a>6 提取数据</h2>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># 调用选析器</span>
<span class="hljs-keyword">await</span> page.waitForXPath(<span class="hljs-string">'//*[@id="page"]'</span>)
<span class="hljs-comment"># 获取 网页 源代码</span>
<span class="hljs-built_in">print</span>(<span class="hljs-keyword">await</span> page.content())
</code></div></pre>
<pre><div class="hljs"><code class="lang-PYTHON"><span class="hljs-comment"># 在页面内执行 document.querySelector, 如果没有元素匹配指定的选择器,返回值是 None</span>
J = querySelector
<span class="hljs-comment"># 在页面内执行 document.querySelector, 然后把匹配到的元素作为第一个参数传给 pageFunction</span>
Jeval = querySelectorEval
<span class="hljs-comment"># 在页面执行document.querySelectorAll, 如果没有元素匹配指定选择器,返回值是 []</span>
JJ = querySelectorAll
<span class="hljs-comment">#在页面执行 Array.from(document.querySelectorAll(selector)), 然后把匹配到的元素作为第一个参数传给 pageFunction</span>
JJeval = querySelectorEval
<span class="hljs-comment"># XPath 表达式</span>
Jx = xpath
</code></div></pre>

评论区