Python 多进程、多线程、异步编程与GPU加速
有勇气的牛排
1457
Python
2024-08-22 22:05:32
前言
多进程:适合CPU密集型任务。
多线程:适合I/O密集型任务,能欧提高并发性。
异步编程:适合I/O密集型任务,通过事件循环实现任务的并发执行。
GPU加速:大规模计算、深度学习。
1 多进程
多进程(Multiprocessing)是实现并行的一种常见方式。
每个进程有自己的独立内存空间。
from multiprocessing import Pool
import math
def compute_factorial(n):
return math.factorial(n)
if __name__ == "__main__":
numbers = [3, 5, 10]
with Pool(processes=2) as pool:
results = pool.map(compute_factorial, numbers)
print(results)
print(results)

2 多线程
多线程(Multithreading)。
import threading
import time
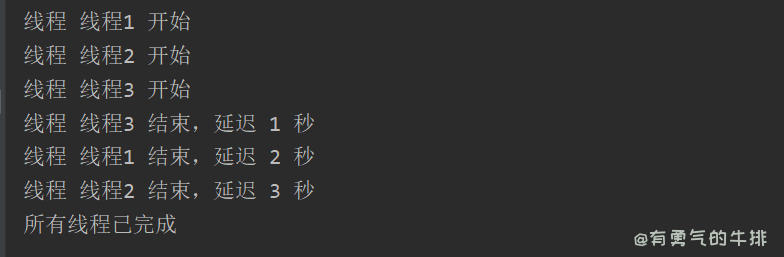
def print_thread_info(thread_name, delay):
"""线程执行的函数"""
print(f"线程 {thread_name} 开始")
time.sleep(delay)
print(f"线程 {thread_name} 结束,延迟 {delay} 秒")
if __name__ == "__main__":
thread1 = threading.Thread(target=print_thread_info, args=("线程1", 2))
thread2 = threading.Thread(target=print_thread_info, args=("线程2", 3))
thread3 = threading.Thread(target=print_thread_info, args=("线程3", 1))
thread1.start()
thread2.start()
thread3.start()
thread1.join()
thread2.join()
thread3.join()
print("所有线程已完成")
3 异步编程
异步异步编程 :Asynchronous Programming
import asyncio
async def fetch_data():
await asyncio.sleep(1)
return "data"
async def main():
tasks = [fetch_data() for _ in range(5)]
results = await asyncio.gather(*tasks)
print(results)
if __name__ == "__main__":
asyncio.run(main())
4 GPU 加速
场景:深度学习、科学计算
import torch
def compute_on_gpu():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.rand(10000, 10000, device=device)
y = torch.rand(10000, 10000, device=device)
z = torch.matmul(x, y)
return z
if __name__ == "__main__":
result = compute_on_gpu()
print(result)
<h2><a id="_0"></a>前言</h2>
<p>多进程:适合CPU密集型任务。</p>
<p>多线程:适合I/O密集型任务,能欧提高并发性。</p>
<p>异步编程:适合I/O密集型任务,通过事件循环实现任务的并发执行。</p>
<p>GPU加速:大规模计算、深度学习。</p>
<h2><a id="1__12"></a>1 多进程</h2>
<p>多进程(Multiprocessing)是实现并行的一种常见方式。</p>
<p>每个进程有自己的独立内存空间。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> multiprocessing <span class="hljs-keyword">import</span> Pool
<span class="hljs-keyword">import</span> math
<span class="hljs-comment"># 计算阶乘</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">compute_factorial</span>(<span class="hljs-params">n</span>):
<span class="hljs-keyword">return</span> math.factorial(n)
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>:
numbers = [<span class="hljs-number">3</span>, <span class="hljs-number">5</span>, <span class="hljs-number">10</span>]
<span class="hljs-comment"># 创建进程,最大2个任务并行处理</span>
<span class="hljs-keyword">with</span> Pool(processes=<span class="hljs-number">2</span>) <span class="hljs-keyword">as</span> pool:
<span class="hljs-comment"># pool.map:分配任务</span>
results = pool.<span class="hljs-built_in">map</span>(compute_factorial, numbers)
<span class="hljs-built_in">print</span>(results)
<span class="hljs-built_in">print</span>(results)
<span class="hljs-comment"># 输出:[6, 120, 3628800]</span>
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/358d2f6a3e66e045523e3b8ee20eae9e.png" alt="python多进程案例 " /></p>
<h2><a id="2__40"></a>2 多线程</h2>
<p>多线程(Multithreading)。</p>
<ul>
<li>
<p>一个进程可以创建多个线程。</p>
</li>
<li>
<p>Python有GIL(全局解释器锁)会限制,即同时只能有一个线程执行。</p>
<p>在I/O密集型任务重,多线程仍然可以提高程序并发性。</p>
</li>
</ul>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> threading
<span class="hljs-keyword">import</span> time
<span class="hljs-keyword">def</span> <span class="hljs-title function_">print_thread_info</span>(<span class="hljs-params">thread_name, delay</span>):
<span class="hljs-string">"""线程执行的函数"""</span>
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"线程 <span class="hljs-subst">{thread_name}</span> 开始"</span>)
time.sleep(delay)
<span class="hljs-built_in">print</span>(<span class="hljs-string">f"线程 <span class="hljs-subst">{thread_name}</span> 结束,延迟 <span class="hljs-subst">{delay}</span> 秒"</span>)
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>:
<span class="hljs-comment"># 创建多个线程</span>
thread1 = threading.Thread(target=print_thread_info, args=(<span class="hljs-string">"线程1"</span>, <span class="hljs-number">2</span>))
thread2 = threading.Thread(target=print_thread_info, args=(<span class="hljs-string">"线程2"</span>, <span class="hljs-number">3</span>))
thread3 = threading.Thread(target=print_thread_info, args=(<span class="hljs-string">"线程3"</span>, <span class="hljs-number">1</span>))
<span class="hljs-comment"># 启动线程</span>
thread1.start()
thread2.start()
thread3.start()
<span class="hljs-comment"># 等待线程完成</span>
thread1.join()
thread2.join()
thread3.join()
<span class="hljs-built_in">print</span>(<span class="hljs-string">"所有线程已完成"</span>)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/e613011d71f3977f04cbcba15fef87ae.png" alt="python多线程案例" /></p>
<h2><a id="3__81"></a>3 异步编程</h2>
<p>异步异步编程 :Asynchronous Programming</p>
<ul>
<li>
<p>通过<strong>事件循环</strong>实现任务的并发执行。</p>
</li>
<li>
<p>不是传统意义上的并行(不使用多个CPU核心),允许在等待I/O执行时,执行其他任务。</p>
</li>
</ul>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> asyncio
<span class="hljs-keyword">async</span> <span class="hljs-keyword">def</span> <span class="hljs-title function_">fetch_data</span>():
<span class="hljs-keyword">await</span> asyncio.sleep(<span class="hljs-number">1</span>) <span class="hljs-comment"># 模拟 I/O 操作</span>
<span class="hljs-keyword">return</span> <span class="hljs-string">"data"</span>
<span class="hljs-keyword">async</span> <span class="hljs-keyword">def</span> <span class="hljs-title function_">main</span>():
tasks = [fetch_data() <span class="hljs-keyword">for</span> _ <span class="hljs-keyword">in</span> <span class="hljs-built_in">range</span>(<span class="hljs-number">5</span>)]
results = <span class="hljs-keyword">await</span> asyncio.gather(*tasks)
<span class="hljs-built_in">print</span>(results)
<span class="hljs-comment"># 输出:['data', 'data', 'data', 'data', 'data']</span>
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>:
asyncio.run(main())
</code></div></pre>
<h2><a id="4_GPU__108"></a>4 GPU 加速</h2>
<p>场景:深度学习、科学计算</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">import</span> torch
<span class="hljs-keyword">def</span> <span class="hljs-title function_">compute_on_gpu</span>():
device = torch.device(<span class="hljs-string">"cuda"</span> <span class="hljs-keyword">if</span> torch.cuda.is_available() <span class="hljs-keyword">else</span> <span class="hljs-string">"cpu"</span>)
x = torch.rand(<span class="hljs-number">10000</span>, <span class="hljs-number">10000</span>, device=device)
y = torch.rand(<span class="hljs-number">10000</span>, <span class="hljs-number">10000</span>, device=device)
z = torch.matmul(x, y)
<span class="hljs-keyword">return</span> z
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>:
result = compute_on_gpu()
<span class="hljs-built_in">print</span>(result)
</code></div></pre>

评论区