前言
灯光、灯光打过来,好,再过来一些,繁体字典准备!action
在處理大文件時,需要注意避免一次性將文件全部加載到內存中,防止內存溢出。
同時,還要關注處理效率,文件訪問模式(順序或隨機)以及最終輸出的位置。
保姆级别案例,参考下文,请尽情的复制粘贴!(忘了记得来翻博客:有勇气的牛排)
1 逐行处理
open(打开文件对象)
打開文件函數 open ,僅僅返回一個文件對象。文件內容並沒有讀取的內存中。
逐行讀取:
在使用 for line in file 或 file.readline() 的時候,文件才會被逐行讀取到內存中。
這種方式只會講當前處理的行加載到內存,而不是整個文件。
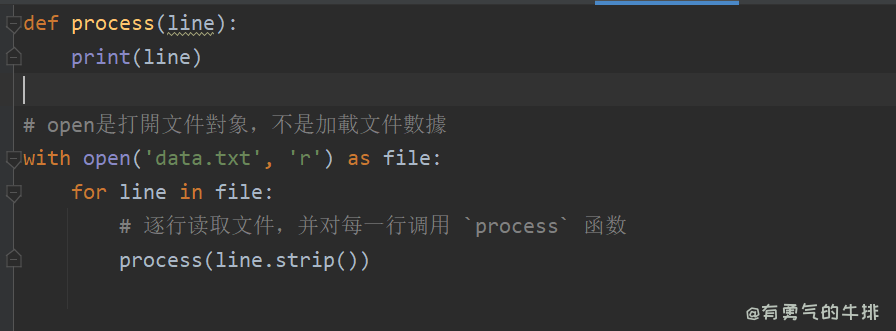
def process(line):
print(line)
with open('data.txt', 'r') as file:
for line in file:
process(line.strip())
2 分块处理
將文件按照固定大小進行
注意:
确保数据不跨行,以免数据截断,如果一定要读取,那就将本次未处理完的数据,拼接到下一次的数据前方。
def process_chunk(chunk):
lines = chunk.split("\r\n")
for line in lines:
print(line)
with open('data.txt', 'rb') as f:
chunk_size = 1024 * 1024
while True:
chunk = f.read(chunk_size)
if not chunk:
break
process_chunk(chunk.decode())
3 使用生成器处理数据(分块)
定义:生成器是一种延迟计算的方式,合适处理大文件和大数据集。
def read_in_chunks(file_object, chunk_size=1024):
while True:
data = file_object.read(chunk_size)
if not data:
break
yield data
with open('data.txt', 'rb') as f:
for chunk in read_in_chunks(f):
chunk = chunk.decode()
lines = chunk.split("\r\n")
for line in lines:
print(line)
4 内存映射文件
定义:使用 mmap 将文件映射到内存中,按需读取文件内容。
4.1 方案一
mport mmap
with open('data.txt', 'r+b') as f:
mmapped_file = mmap.mmap(f.fileno(), 0)
for line in iter(mmapped_file.readline, b""):
print(line.decode().replace('\r\n', ''))
mmapped_file.close()
优点:简洁、比方案2稍微占内存
适合逐行处理的场景
4.1 方案二 (推荐)
from mmap import mmap
def get_lines(filename):
with open(filename, 'r+') as f:
m = mmap(f.fileno(), 0)
tmp = 0
for i, char in enumerate(m):
if char == b'\n':
yield m[tmp:i + 1]
tmp = i + 1
if __name__ == '__main__':
for line in get_lines('data.txt'):
line = line.decode().replace('\r\n', '')
print(line)
优点:
生成器模式,按需读取数据,可自定义控制数据结尾符号
适合自定义切割数据的场景
<h2><a id="_0"></a>前言</h2>
<p><strong>灯光、灯光</strong>打过来,好,再过来一些,<strong>繁体字典准备!action</strong></p>
<p>在處理大文件時,需要注意避免一次性將文件全部加載到內存中,防止內存溢出。</p>
<p>同時,還要關注處理效率,文件訪問模式(順序或隨機)以及最終輸出的位置。</p>
<p>保姆级别案例,参考下文,请尽情的复制粘贴!<strong>(忘了记得来翻博客:有勇气的牛排)</strong></p>
<h2><a id="1__12"></a>1 逐行处理</h2>
<p>open(打开文件对象)</p>
<p>打開文件函數 <code>open</code> ,僅僅返回一個文件對象。文件內容並沒有讀取的內存中。</p>
<p>逐行讀取:</p>
<p>在使用 <code>for line in file</code> 或 <code>file.readline()</code> 的時候,文件才會被逐行讀取到內存中。</p>
<p>這種方式只會講當前處理的行加載到內存,而不是整個文件。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">def</span> <span class="hljs-title function_">process</span>(<span class="hljs-params">line</span>):
<span class="hljs-built_in">print</span>(line)
<span class="hljs-comment"># open是打開文件對象,不是加載文件數據</span>
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(<span class="hljs-string">'data.txt'</span>, <span class="hljs-string">'r'</span>) <span class="hljs-keyword">as</span> file:
<span class="hljs-keyword">for</span> line <span class="hljs-keyword">in</span> file:
<span class="hljs-comment"># 逐行读取文件,并对每一行调用 `process` 函数</span>
process(line.strip())
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/998e51b28fd2e024dcb84e3f3379d95e.png" alt="python逐行处理数据" /></p>
<h2><a id="2__39"></a>2 分块处理</h2>
<p>將文件按照固定大小進行</p>
<p>注意:</p>
<p>确保数据不跨行,以免数据截断,如果一定要读取,那就将本次未处理完的数据,拼接到下一次的数据前方。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">def</span> <span class="hljs-title function_">process_chunk</span>(<span class="hljs-params">chunk</span>):
lines = chunk.split(<span class="hljs-string">"\r\n"</span>)
<span class="hljs-keyword">for</span> line <span class="hljs-keyword">in</span> lines:
<span class="hljs-built_in">print</span>(line)
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(<span class="hljs-string">'data.txt'</span>, <span class="hljs-string">'rb'</span>) <span class="hljs-keyword">as</span> f:
chunk_size = <span class="hljs-number">1024</span> * <span class="hljs-number">1024</span> <span class="hljs-comment"># 1 MB</span>
<span class="hljs-keyword">while</span> <span class="hljs-literal">True</span>:
chunk = f.read(chunk_size)
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> chunk:
<span class="hljs-keyword">break</span>
process_chunk(chunk.decode())
</code></div></pre>
<h2><a id="3__64"></a>3 使用生成器处理数据(分块)</h2>
<p>定义:生成器是一种延迟计算的方式,合适处理大文件和大数据集。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">def</span> <span class="hljs-title function_">read_in_chunks</span>(<span class="hljs-params">file_object, chunk_size=<span class="hljs-number">1024</span></span>):
<span class="hljs-keyword">while</span> <span class="hljs-literal">True</span>:
data = file_object.read(chunk_size)
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> data:
<span class="hljs-keyword">break</span>
<span class="hljs-keyword">yield</span> data
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(<span class="hljs-string">'data.txt'</span>, <span class="hljs-string">'rb'</span>) <span class="hljs-keyword">as</span> f:
<span class="hljs-keyword">for</span> chunk <span class="hljs-keyword">in</span> read_in_chunks(f):
chunk = chunk.decode()
lines = chunk.split(<span class="hljs-string">"\r\n"</span>)
<span class="hljs-keyword">for</span> line <span class="hljs-keyword">in</span> lines:
<span class="hljs-built_in">print</span>(line)
</code></div></pre>
<h2><a id="4__87"></a>4 内存映射文件</h2>
<p>定义:使用 mmap 将文件映射到内存中,按需读取文件内容。</p>
<h3><a id="41__91"></a>4.1 方案一</h3>
<pre><div class="hljs"><code class="lang-python">mport mmap
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(<span class="hljs-string">'data.txt'</span>, <span class="hljs-string">'r+b'</span>) <span class="hljs-keyword">as</span> f:
mmapped_file = mmap.mmap(f.fileno(), <span class="hljs-number">0</span>)
<span class="hljs-keyword">for</span> line <span class="hljs-keyword">in</span> <span class="hljs-built_in">iter</span>(mmapped_file.readline, <span class="hljs-string">b""</span>):
<span class="hljs-built_in">print</span>(line.decode().replace(<span class="hljs-string">'\r\n'</span>, <span class="hljs-string">''</span>))
mmapped_file.close()
</code></div></pre>
<p>优点:简洁、比方案2稍微占内存</p>
<p>适合逐行处理的场景</p>
<h3><a id="41___107"></a>4.1 方案二 (推荐)</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-keyword">from</span> mmap <span class="hljs-keyword">import</span> mmap <span class="hljs-comment"># 从 mmap 模块导入 mmap 类,用于内存映射文件</span>
<span class="hljs-keyword">def</span> <span class="hljs-title function_">get_lines</span>(<span class="hljs-params">filename</span>):
<span class="hljs-comment"># 定义一个生成器函数 get_lines,用于按行读取指定文件</span>
<span class="hljs-keyword">with</span> <span class="hljs-built_in">open</span>(filename, <span class="hljs-string">'r+'</span>) <span class="hljs-keyword">as</span> f:
<span class="hljs-comment"># 以读写模式 ('r+') 打开文件,并将文件对象绑定到变量 f 上</span>
m = mmap(f.fileno(), <span class="hljs-number">0</span>)
<span class="hljs-comment"># 使用文件描述符创建内存映射对象 m。0 表示映射整个文件</span>
tmp = <span class="hljs-number">0</span>
<span class="hljs-comment"># 初始化 tmp 变量,用于记录每一行的开始位置</span>
<span class="hljs-keyword">for</span> i, char <span class="hljs-keyword">in</span> <span class="hljs-built_in">enumerate</span>(m):
<span class="hljs-comment"># 使用枚举 (enumerate) 遍历内存映射对象 m 中的每一个字符</span>
<span class="hljs-keyword">if</span> char == <span class="hljs-string">b'\n'</span>:
<span class="hljs-comment"># 如果当前字符是换行符 (b'\n'),则表示找到了一行的结束</span>
<span class="hljs-keyword">yield</span> m[tmp:i + <span class="hljs-number">1</span>]
<span class="hljs-comment"># 使用 yield 生成从 tmp 到当前索引 i + 1 的字节串,表示一行的内容</span>
tmp = i + <span class="hljs-number">1</span>
<span class="hljs-comment"># 更新 tmp 为当前换行符的位置的下一位置,以便处理下一行</span>
<span class="hljs-comment"># 结束文件映射处理</span>
<span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">'__main__'</span>:
<span class="hljs-comment"># 确保以下代码块仅在直接运行脚本时执行,而不是在被导入时执行</span>
<span class="hljs-keyword">for</span> line <span class="hljs-keyword">in</span> get_lines(<span class="hljs-string">'data.txt'</span>):
<span class="hljs-comment"># 调用 get_lines 函数,逐行读取 'data.txt' 文件</span>
line = line.decode().replace(<span class="hljs-string">'\r\n'</span>, <span class="hljs-string">''</span>)
<span class="hljs-comment"># 将字节串解码为字符串,并替换掉可能存在的 '\r\n'(Windows 风格的换行符),以统一为 '\n'</span>
<span class="hljs-built_in">print</span>(line)
<span class="hljs-comment"># 输出每一行内容</span>
</code></div></pre>
<p>优点:</p>
<p>生成器模式,按需读取数据,可自定义控制数据结尾符号</p>
<p>适合自定义切割数据的场景</p>

评论区