Python 数据类型 列表 常见问答
复杂度举例
for i in list_a O(n)
每次循环 i 会从 列表中去除一个元素,即复杂度为O(n)。
list_a = [1, 2, 3]
for i in list_a:
if i in list_a O(n)
list_a = [1, 2, 3, 4, 5]
x = 5
if x in list_a:
print("okk")
如果 x=1,只需要比较1次。
如果 x=5,需要比较5次。
如果 x=100,需要比较完整列表,仍然找不到哦。
所以在最坏情况下,需要比较n此,故时间复杂度为O(n)。
列表去重
set方法
原理:将列表转为 set 集合(自动去重),然后在转为list。
输出不能保证顺序,因为 set 是无序集合。
num_list = [1, 2, 3, 2, 1]
print(list(set(num_list)))
使用循环 + in 判断
num_list = [1, 2, 3, 2, 1]
unique_list = []
for i in num_list:
if i not in unique_list:
unique_list.append(i)
print(unique_list)
使用 dict.fromkeys()
在python3.6开始,此方法有序。
num_list = [1, 2, 3, 2, 1]
print(dict.fromkeys(num_list))
print(list(dict.fromkeys(num_list)))
字符串切割为列表
将 “1,2,3” 转 [“1”,“2”,“3”]
s = "1,2,3"
print(s.split(","))
给定2个 list,A和B,找出相同元素和不同元素
方法一:使用循环(列表推导式)
list_a = [1, 2, 3, 3, 4, 5, 6]
list_b = [1, 3, 5]
same_list = [i for i in list_a if i in list_b]
diff_list = [i for i in list_a if i not in list_b]
print(same_list)
print(diff_list)
✔优点:
- 保持元素顺序:
same_list 和 diff_list 中的元素保持了第一个列表的顺序。
- 可处理重复元素(不丢失):如果
list_a或list_b 中有重复元素,会保留它们,适合对重复敏感的场景。
❌ 缺点:
-
效率低下:for i in list_a 的复杂度为 O(n),整体复杂度如下:
same_list: O(m*n)
diff_list: O(m*n)
其中 m = len(list_a),n = len(list_b)。
方法二:使用集合运算(set 与、或、异或)
list_a = [1, 2, 3, 4, 5, 6]
list_b = [1, 3, 5]
same_list = list(set(list_a) & set(list_b))
diff_list = list(set(list_a) ^ set(list_b))
print(same_list)
print(diff_list)
整体复杂度:
O(m + n)
✔优点:
- 效率高:集合操作是基于哈希表,查找和交并差操作平均复杂度为 O(1)。
- 代码简洁直观:使用集合操作可以一行搞定交集、差集、并集等。
❌ 缺点:
- 去重:集合会自动去重,丢失重复元素信息。
- 顺序丢失:集合是无需结构,输出结果顺序肯呢个与原始列表不同。
- 只适用于可哈希类型。
保留顺序又提高性能
set_b = set(list_b)
same_list = [i for i in list_a if i in set_b]
diff_list = [i for i in list_a if i not in set_b]
这样可以将 in list_b 的O(n)降为 O(1)。
建议
方法一:数据量小、需要保留顺序、重复值。
方法二:数据量大、对性能敏感、重复性不重要。
方法三:保留一个的顺序,部分提高性能。
展开该列表 [[1,2],[3,4],[5,6]]为单列表
用一行代码展开该列表 [[1,2],[3,4],[5,6]],得出[1,2,3,4,5,6]
mm = [[1, 2], [3, 4], [5, 6]]
print([j for i in mm for j in i])
合并列表
使用加号 +(返回新列表)
a = [1, 3, 5]
b = [2, 4, 6]
print(a+b)
a = [1, 3, 5]
b = [2, 4, 6]
a += b
print(a)
extend(就地修改)
a = [1, 3, 5]
b = [2, 4, 6]
a.extend(b)
print(a)
使用*unpacking (推荐灵活)
a = [1, 3, 5]
b = [2, 4, 6]
c = [*a, *b]
print(c)
使用 itertools.chain() (生成器,内存友好)
合并大数据时更高效,适合性能要求高的场景。
from itertools import chain
a = [1, 3, 5]
b = [2, 4, 6]
c = [7, 8, 9]
d = list(chain(a, b, c))
print(d)
列表 打乱顺序/随机排序
radom.shuffle() 就地修改
特点:
- 原地修改(不返回新列表)
- 返回值为 None
- 会改变原始列表内容
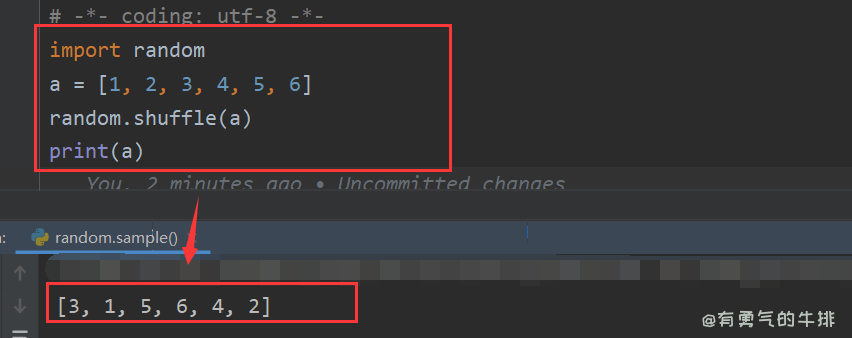
# -*- coding: utf-8 -*-
import random
a = [1, 2, 3, 4, 5, 6]
random.shuffle(a)
print(a)
radom.sample() 返回新列表
特点:
- 不会修改原始列表
- 返回一个新的乱序副本
- k 是指定要返回多少个元素
import random
a = [1, 2, 3, 4, 5, 6]
shuffled = random.sample(a, k=len(a))
print(shuffled)
<h1><a id="Python____0"></a>Python 数据类型 列表 常见问答</h1>
<h2><a id="_2"></a>复杂度举例</h2>
<h3><a id="for_i_in_list_a_On_4"></a><code>for i in list_a</code> O(n)</h3>
<p>每次循环 <code>i</code> 会从 列表中去除一个元素,即复杂度为O(n)。</p>
<pre><div class="hljs"><code class="lang-python">list_a = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>] <span class="hljs-comment"># 长度 n=3</span>
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> list_a:
<span class="hljs-comment"># 每循环一次为O(1) </span>
</code></div></pre>
<h3><a id="if_i_in_list_a_On_15"></a><code>if i in list_a</code> O(n)</h3>
<pre><div class="hljs"><code class="lang-python">list_a = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">4</span>, <span class="hljs-number">5</span>]
x = <span class="hljs-number">5</span>
<span class="hljs-keyword">if</span> x <span class="hljs-keyword">in</span> list_a:
<span class="hljs-built_in">print</span>(<span class="hljs-string">"okk"</span>)
</code></div></pre>
<p>如果 <code>x=1</code>,只需要比较1次。</p>
<p>如果 <code>x=5</code>,需要比较5次。</p>
<p>如果 <code>x=100</code>,需要比较完整列表,仍然找不到哦。</p>
<p>所以在最坏情况下,需要比较<code>n</code>此,故<strong>时间复杂度为O(n)</strong>。</p>
<h2><a id="_35"></a>列表去重</h2>
<h3><a id="set_37"></a>set方法</h3>
<p>原理:将列表转为 <code>set</code> 集合(自动去重),然后在转为list。</p>
<p>输出不能保证顺序,因为 <code>set</code> 是无序集合。</p>
<pre><div class="hljs"><code class="lang-python">num_list = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">2</span>, <span class="hljs-number">1</span>]
<span class="hljs-built_in">print</span>(<span class="hljs-built_in">list</span>(<span class="hljs-built_in">set</span>(num_list)))
</code></div></pre>
<h3><a id="__in__48"></a>使用循环 + <code>in</code> 判断</h3>
<pre><div class="hljs"><code class="lang-python">num_list = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">2</span>, <span class="hljs-number">1</span>]
unique_list = []
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> num_list:
<span class="hljs-keyword">if</span> i <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> unique_list:
unique_list.append(i)
<span class="hljs-built_in">print</span>(unique_list)
</code></div></pre>
<h3><a id="_dictfromkeys_60"></a>使用 <code>dict.fromkeys()</code></h3>
<p>在python3.6开始,此方法有序。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
num_list = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">2</span>, <span class="hljs-number">1</span>]
<span class="hljs-built_in">print</span>(<span class="hljs-built_in">dict</span>.fromkeys(num_list)) <span class="hljs-comment"># {1: None, 2: None, 3: None}</span>
<span class="hljs-built_in">print</span>(<span class="hljs-built_in">list</span>(<span class="hljs-built_in">dict</span>.fromkeys(num_list))) <span class="hljs-comment"># [1, 2, 3]</span>
</code></div></pre>
<h2><a id="_72"></a>字符串切割为列表</h2>
<h3><a id="_123___123_74"></a>将 “1,2,3” 转 [“1”,“2”,“3”]</h3>
<pre><div class="hljs"><code class="lang-python">s = <span class="hljs-string">"1,2,3"</span>
<span class="hljs-built_in">print</span>(s.split(<span class="hljs-string">","</span>))
<span class="hljs-comment"># 输出:['1', '2', '3']</span>
</code></div></pre>
<h2><a id="2_listAB_82"></a>给定2个 list,A和B,找出相同元素和不同元素</h2>
<h3><a id="_84"></a>方法一:使用循环(列表推导式)</h3>
<pre><div class="hljs"><code class="lang-python">list_a = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">3</span>, <span class="hljs-number">4</span>, <span class="hljs-number">5</span>, <span class="hljs-number">6</span>]
list_b = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
same_list = [i <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> list_a <span class="hljs-keyword">if</span> i <span class="hljs-keyword">in</span> list_b]
diff_list = [i <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> list_a <span class="hljs-keyword">if</span> i <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> list_b]
<span class="hljs-built_in">print</span>(same_list)
<span class="hljs-built_in">print</span>(diff_list)
</code></div></pre>
<p>✔优点:</p>
<ul>
<li><strong>保持元素顺序</strong>:<code>same_list</code> 和 <code>diff_list</code> 中的元素保持了第一个列表的顺序。</li>
<li><strong>可处理重复元素(不丢失)</strong>:如果 <code>list_a</code>或<code>list_b </code>中有重复元素,会保留它们,适合对重复敏感的场景。</li>
</ul>
<p>❌ 缺点:</p>
<ul>
<li>
<p>效率低下:<code>for i in list_a</code> 的复杂度为 O(n),整体复杂度如下:</p>
<pre><div class="hljs"><code class="lang-shell">same_list: O(m*n)
diff_list: O(m*n)
</code></div></pre>
<p>其中 <code>m = len(list_a)</code>,<code>n = len(list_b)</code>。</p>
</li>
</ul>
<h3><a id="set__112"></a>方法二:使用集合运算(<code>set</code> 与、或、异或)</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
list_a = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">4</span>, <span class="hljs-number">5</span>, <span class="hljs-number">6</span>]
list_b = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
same_list = <span class="hljs-built_in">list</span>(<span class="hljs-built_in">set</span>(list_a) & <span class="hljs-built_in">set</span>(list_b)) <span class="hljs-comment"># 交集</span>
diff_list = <span class="hljs-built_in">list</span>(<span class="hljs-built_in">set</span>(list_a) ^ <span class="hljs-built_in">set</span>(list_b)) <span class="hljs-comment"># 对称差集</span>
<span class="hljs-built_in">print</span>(same_list) <span class="hljs-comment"># 输出:[1, 3, 5]</span>
<span class="hljs-built_in">print</span>(diff_list) <span class="hljs-comment"># 输出:[2, 4, 6]</span>
</code></div></pre>
<p>整体复杂度:</p>
<pre><div class="hljs"><code class="lang-shell">O(m + n)
</code></div></pre>
<p>✔优点:</p>
<ul>
<li><strong>效率高</strong>:<strong>集合操作</strong>是基于哈希表,查找和交并差操作<strong>平均复杂度为 O(1)</strong>。</li>
<li>代码简洁直观:使用集合操作可以一行搞定交集、差集、并集等。</li>
</ul>
<p>❌ 缺点:</p>
<ul>
<li>去重:集合会自动去重,丢失重复元素信息。</li>
<li>顺序丢失:集合是无需结构,输出结果顺序肯呢个与原始列表不同。</li>
<li>只适用于可哈希类型。</li>
</ul>
<h3><a id="_142"></a>保留顺序又提高性能</h3>
<pre><div class="hljs"><code class="lang-python">set_b = <span class="hljs-built_in">set</span>(list_b)
same_list = [i <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> list_a <span class="hljs-keyword">if</span> i <span class="hljs-keyword">in</span> set_b]
diff_list = [i <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> list_a <span class="hljs-keyword">if</span> i <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> set_b]
</code></div></pre>
<p>这样可以将 <code>in list_b</code> 的O(n)降为 O(1)。</p>
<h3><a id="_154"></a>建议</h3>
<p>方法一:数据量小、需要保留顺序、重复值。</p>
<p>方法二:数据量大、对性能敏感、重复性不重要。</p>
<p>方法三:保留一个的顺序,部分提高性能。</p>
<h2><a id="_123456_164"></a>展开该列表 [[1,2],[3,4],[5,6]]为单列表</h2>
<p>用一行代码展开该列表 [[1,2],[3,4],[5,6]],得出[1,2,3,4,5,6]</p>
<pre><div class="hljs"><code class="lang-python">mm = [[<span class="hljs-number">1</span>, <span class="hljs-number">2</span>], [<span class="hljs-number">3</span>, <span class="hljs-number">4</span>], [<span class="hljs-number">5</span>, <span class="hljs-number">6</span>]]
<span class="hljs-built_in">print</span>([j <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> mm <span class="hljs-keyword">for</span> j <span class="hljs-keyword">in</span> i])
</code></div></pre>
<h2><a id="_173"></a>合并列表</h2>
<h3><a id="__175"></a>使用加号 <code>+</code>(返回新列表)</h3>
<pre><div class="hljs"><code class="lang-python">a = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
b = [<span class="hljs-number">2</span>, <span class="hljs-number">4</span>, <span class="hljs-number">6</span>]
<span class="hljs-built_in">print</span>(a+b)
</code></div></pre>
<pre><div class="hljs"><code class="lang-python">a = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
b = [<span class="hljs-number">2</span>, <span class="hljs-number">4</span>, <span class="hljs-number">6</span>]
a += b
<span class="hljs-built_in">print</span>(a)
</code></div></pre>
<h3><a id="extend_191"></a>extend(就地修改)</h3>
<pre><div class="hljs"><code class="lang-python">a = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
b = [<span class="hljs-number">2</span>, <span class="hljs-number">4</span>, <span class="hljs-number">6</span>]
a.extend(b)
<span class="hljs-built_in">print</span>(a)
</code></div></pre>
<h3><a id="unpacking__201"></a>使用*unpacking (推荐灵活)</h3>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
a = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
b = [<span class="hljs-number">2</span>, <span class="hljs-number">4</span>, <span class="hljs-number">6</span>]
c = [*a, *b]
<span class="hljs-built_in">print</span>(c)
</code></div></pre>
<h3><a id="_itertoolschain__212"></a>使用 <code>itertools.chain()</code> (生成器,内存友好)</h3>
<p>合并大数据时更高效,适合性能要求高的场景。</p>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">from</span> itertools <span class="hljs-keyword">import</span> chain
a = [<span class="hljs-number">1</span>, <span class="hljs-number">3</span>, <span class="hljs-number">5</span>]
b = [<span class="hljs-number">2</span>, <span class="hljs-number">4</span>, <span class="hljs-number">6</span>]
c = [<span class="hljs-number">7</span>, <span class="hljs-number">8</span>, <span class="hljs-number">9</span>]
d = <span class="hljs-built_in">list</span>(chain(a, b, c))
<span class="hljs-built_in">print</span>(d)
</code></div></pre>
<h2><a id="__228"></a>列表 打乱顺序/随机排序</h2>
<h3><a id="radomshuffle__230"></a><code>radom.shuffle()</code> 就地修改</h3>
<p>特点:</p>
<ul>
<li>原地修改(不返回新列表)</li>
<li>返回值为 None</li>
<li>会改变原始列表内容</li>
</ul>
<pre><div class="hljs"><code class="lang-shell"><span class="hljs-meta"># </span><span class="language-bash">-*- coding: utf-8 -*-</span>
import random
a = [1, 2, 3, 4, 5, 6]
random.shuffle(a)
print(a)
</code></div></pre>
<p><img src="https://www.couragesteak.com/tcos/article/22cae7cea5989f5401b318b9874a9bfb.png" alt="image.png" /></p>
<h3><a id="radomsample__248"></a><code>radom.sample()</code> 返回新列表</h3>
<p>特点:</p>
<ul>
<li>不会修改原始列表</li>
<li>返回一个新的乱序副本</li>
<li>k 是指定要返回多少个元素</li>
</ul>
<pre><div class="hljs"><code class="lang-python"><span class="hljs-comment"># -*- coding: utf-8 -*-</span>
<span class="hljs-keyword">import</span> random
a = [<span class="hljs-number">1</span>, <span class="hljs-number">2</span>, <span class="hljs-number">3</span>, <span class="hljs-number">4</span>, <span class="hljs-number">5</span>, <span class="hljs-number">6</span>]
shuffled = random.sample(a, k=<span class="hljs-built_in">len</span>(a))
<span class="hljs-built_in">print</span>(shuffled)
</code></div></pre>

评论区